

En la primera parte de este artículo, vimos el concepto de analizador léxico y mostramos una implementación sencilla usando una clase en Object Pascal.
En esta parte, enseñaré como usar la librería SynFacilSyn para implementar un analizador léxico más completo y como lo podemos usar para el resaltado de sintaxis de un texto.
Si nunca ha usado SynFacilSyn, puede que le resulte extraño, la forma como este bicho funciona. SynFacilSyn, es primordialmente, un resaltador de sintaxis para el control SynEdit de Lazarus. Pero SynFacilSyn, no es un resaltador de sintaxis cualquiera, sino que es un resaltador de sintaxis configurable, definible, «scriptable», como se le suele decir en terminología inglesa. Esto significa que la sintaxis que resalta, puede ser definida por por el usuario (a diferencia de otros resaltadores para SynEdit, que ya vienen con una sintaxis fija).
La forma como trabaja un resaltador, es similar a la de un lexer: Extrae tokens. En el fondo, podríamos decir que todo resaltador de sintaxis, es además un lexer. Y si ahora agregamos las características de flexibilidad que tiene SynFacilSyn, pues entonces tenemos un excelente lexer, que podemos usar para algo más, que el resaltado de sintaxis.
SynFacilSyn, admite dos formas de configuración:
- Eneteramente por código.
- Usando un archivo XML, externo.
En este caso, explicaré solo la primera forma. Para obteenr información sobre uso de el XML externo., se recomienda leer la documentación de SynFacilSyn.
Para definir nuestra sintaxis, debemos crear una instancia de TSynFacilSyn:
xLex := TSynFacilSyn.Create(nil); //crea lexer //hace algo con el lexer ... xLex.Destroy;
Lo primero que debemos tener en cuenta es que todos los tokens, manejados por SynFacilSyn, deben pertenecer a un tipo. SynFacilSyn, viene ya con tipos de tokens, creados de fábrica. Estos son:
- tkEol -> Saltos de línea
- tkSpace -> Espacios en blanco
- tkSymbol -> Símbolos
- tkIdentif -> Identificadores
- tkNumber -> Números
- tkKeyword -> Palabras clave
- tkString -> Cadenas
- tkComment -> Comentarios
Todos los tokens extraídos de un texto, deben pertenecer a esta lista de tokens. Si esta lista no es suficiente, SynFacilSyn permite crear tipos adicionales de tokens.
Hay algunas normas que siguen los resaltadores de sintaxis con SynFacilSyn:
- Las definiciones de los tokens tkEol y tkSpace, existen siempre y son fijas. No pueden cambiarse. Es decir, que los caracteres que se consideran como saltos de línea o espacios son siempre los mismos.
- La definición de símbolos, no es configurable directamente; se fija por defecto. Todos los tokens que no sean identificados como de cualquier otro tipo, serán considerados como símbolos.
- Las palabras claves, son un subconjunto de los identificadores. Esto es, toda palabra clave es además un identificador.
Esta lista, para nada exhaustiva, muestra algunas características y limitaciones de SynFacilSyn, para manejar tokens.
De acuerdo a lo mencionado, podemos intuir entonces, que al inicio SynFacilSyn, reconoce ya una sintaxis, sin necesidad de configurar nada. Esta sintaxis, se resumiría en: «Lo que no es un salto de línea o espacio, es un símbolo».
Si aplicamos esto a un texto como:
En cualquier lugar: 1+1=3.
Entonces, nuestro SynFacilSyn extraerá los siguientes tokens:
Symbol : En Space : Symbol : cualquier Symbol : lugar: Space : Symbol : 1+1=3.
Aunque funcional, este no es probablemente el comportamiento que esperaríamos de nuestro lexer. Notar que la palabra «lugar», se ha juntado con el símbolo»:», ya que el lexer no reconoce lo que es un identificador (En la práctica, SynFacilSyn viene por defecto con una definición de identificador). Además, los números no se reconocen como tokens, a pesar de que exista ya el tipo tkNumber. Esto se debe a que no existe una definición creada para el tipo Número.
Hay que notar también, que se ha obviado el token tkEol, que sería el salto de línea, pero internamente SynFacilSyn, lo considera siempre.
Veamos como configuraríamos una mejor sintaxis, en nuestro archivo XML:
xLex := TSynFacilSyn.Create(nil); //crea lexer
//Define la sintaxis del lexer
xLex.ClearMethodTables; //limpìa tabla de métodos
xLex.ClearSpecials; //para empezar a definir tokens
//crea tokens por contenido
xLex.DefTokIdentif('[$A-Za-z_]', '[A-Za-z0-9_]*');
xLex.DefTokContent('[0-9]', '[0-9.]*', xLex.tkNumber);
//define palabras clave
xLex.AddIdentSpecList('hola mundo cruel', xLex.tkKeyword);
xLex.Rebuild;
...
xLex.Destroy;
Esta definición, ya permite reconocer números, e incluye una definición para los identificadores. Además, se definen 3 palabras claves «hola», «mundo» y «cruel».
Los identificadores y números son lo que se llama «Tokens por contenido», una definición que se hace, indicando los caracteres que componen al token. Existe otro tipo de token, llamado «Tokens delimitados», y se define indicando los delimitadores inicial y final.
Notar que la definición de los identificadores y números, usa expresiones regulares, en dos partes. La primera parte corresponde al carácter inicial del token, y la siguiente corresponde a los caracteres siguientes. Esta es la forma como trabaja SynFacilSyn.
La expresión regular: [$A-Za-z_] es una lista de caracteres posible para el primer carácter, mientras que [A-Za-z0-9_]* indica un conjunto de caracteres que se puede repetir cero o más veces. Estas expresiones deberían resultarle natural a quien maneje expresiones regulares. De todas formas hay amplia documentación en la Web sobre expresiones regulares.
El soporte para expresiones regulares, es algo pobre en SynFacilSyn, pero esto obedece a que la librería se enfoca más en velocidad que en flexibilidad. Y eso es bastante cierto, ya que un resaltador de sintaxis implementado con SynFacilSyn, es más rápido que los que ofrece nativamente el mismo Lazarus, aún con mejores características.
Ahora que tenemos una mejor definición, podríamos intentar aplicar el lexer al mismo texto:
En cualquier lugar: 1+1=3.
Pero ahora obtendríamos:
Identifier : En Space : Identifier : cualquier Identifier : lugar Symbol : : Space : Number : 1 Symbol : + Number : 1 Symbol : = Number : 3.
Ahora podemos notar una mejoría con respecto a la extracción de tokens, ya que se ha maneja definiciones para los identificadores y los números.
El código usado, para extraer los tokens, sería:
//Explora
xLex.ResetRange;
for lin in SynEdit1.lines do begin
xLex.SetLine(lin,0);
while not xLex.GetEol do begin
Token := xLex.GetToken; //lee el token
TokenType := xLex.GetTokenKind; //lee atributo
//muestra
xLex.Next; //pasa al siguiente
end;
end;
Un detalle importante, es que SynFacilSyn hace exploración por líneas, por eso la exploración, se debe realizar para cada línea del texto.
En este caso, se está leyendo el contenido de SynEdit1.Lines, pero se puede leer también un control «Memo» o cualquier control, que almacene su contenido en un objeto TStrings.
Como un plus, es posible usar este lexer como resaltador de sintaxis para un control SynEdit:
SynEdit1.Highlighter := xLex
y así podríamos ver coloreados, los diversos tokens en la pantalla:
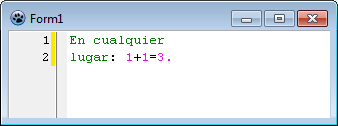
Como se puede ver, usar SynFacilSyn, no ofrece mayor dificultad, asumiendo que conocemos la configuración de tokens.
Existen otras librerías, aparte de SynFacilSyn, que son verdaderos lexers, y con mejores opciones de configuración, pero aquí hemos usado SynFacilSyn, como una muestra de lo que esta librería ofrece. Y una de sus mayores ventajas, es que se puede ver «en tiempo real», como trabaja nuestro lexer, en lugar de solo ver las definiciones abstractas.
![]() ¿Cómo citar este artículo?
¿Cómo citar este artículo?
- En APA: Hinostroza, T. (10 de enero de 2017). Jugando con Palabras – Analizadores Léxicos II. Blog de Tito. https://blogdetito.com/2017/01/10/jugando-con-palabras-analizadores-lexicos-ii/
- En IEEE: T. Hinostroza. (2017, enero 10). Jugando con Palabras – Analizadores Léxicos II. Blog de Tito. [Online]. Available: https://blogdetito.com/2017/01/10/jugando-con-palabras-analizadores-lexicos-ii/
- En ICONTEC: HINOSTROZA, Tito. Jugando con Palabras – Analizadores Léxicos II [blog]. Blog de Tito. Lima Perú. 10 de enero de 2017. Disponible en: https://blogdetito.com/2017/01/10/jugando-con-palabras-analizadores-lexicos-ii/
Dejar una contestacion