

16.1 Introducción
En el capítulo anterior terminamos de implementar el soporte para las condicionales a nuestro compilador Titan, usando macros especiales del MASM32.
Siguiendo este mismo método de trabajo, en este capítulo vamos a implementar soporte a nuestro compilador para las estructuras repetitivas WHILE, que es la única estructura de bucle que tiene nuestro lenguaje Titan.
16.2 Teoría de Compiladores
Generación de Código
En el diseño de un compilador, es necesario siempre incluir el módulo de Generador de Código o Síntesis, que es el que se encarga de crear el código que será el producto final del compilador, es decir, el código objeto (ensamblador, código binario, lenguaje intermedio, código de alto nivel, etc).
La generación de código es un tema algo oscuro y complejo. En comparación con el análisis léxico y sintáctico, existe poca documentación, estándares, librerías y marcos de trabajo.
Uno de los motivos podría ser que, a diferencia de un lexer o parser, el generador de código (al menos para compiladores a código nativo) está muy amarrado a la arquitectura de la máquina para la cual compila, y por ello se pueden tener diseños muy diferentes en cada caso.
La necesidad de poder generar código para diferentes arquitecturas, muchas veces motiva a la creación de un código intermedio, más sencillo, que luego puede ser traducido, con menos esfuerzo, a diferentes arquitecturas. No confundir este proceso con compiladores como Java o .NET que compilan a un código intermedio como producto final. Los compiladores a código nativo pueden tener varias representaciones intermedias, pero esta son solo temporales, y desaparecen cuando se obtiene el código binario/objeto final.
La fuente de información (el alimento) para un generador de código puede ser:
- El mismo código fuente o programa fuente. Se genera código objeto directamente mientras se explora el programa fuente. Tal es el caso de los compiladores muy simples de una sola pasada.
- Alguna representación intermedia del código fuente. Esta es la forma común en que trabajan los compiladores modernos.
Cuando se elige una Representación Intermedia para la síntesis de código, se suele elegir una representación intermedia de bajo nivel que sea parecida al lenguaje ensamblador o el código de tres direcciones. Pero podría usarse cualquier otra como el árbol de sintaxis.
En realidad ni hay magia en la generación de código, sino más bien un nivel de complejidad grande. Salvando el escollo de la conversión de instrucciones a sus correspondientes códigos máquina, la generación de código es casi un trabajo rutinario. El mayor problema reside en poder generar código de forma óptima, que es lo que se espera de un compilador moderno.
Muchos compiladores, que compilan a código nativo, no generan directamente el programa ejecutable binario por la complejidad que implica la construcción de dicho ejecutable, sino más bien, generan una salida en lenguaje ensamblador y luego, con la ayuda de un ensamblador externo, producen el ejecutable final.
Un ensamblador puede producir código ejecutable directamente, pero puede necesitar también de un enlazador, como se muestra en la figura. No confundir el bloque «Código objeto» con el término «Código objeto» que se usa para describir la salida final de un compilador.
La necesidad de un ensamblador-enlazador (externo o interno) se hace necesario cuando el destino de la compilación va a correr en un sistema operativo complejo y sobre una arquitectura de hardware compleja como suelen encontrarse en las computadoras modernas. La construcción de un ejecutable par estos destinos, involucra una complejidad considerable que es mejor dejarla en las manos de un ensamblador y su enlazador.
Existen en la actualidad «frameworks » como LLVM que ayudan en la creación de generadores de código, pero son sistemas complejos y no siempre se adapta a la arquitectura que vamos a manejar.
Pero para muchos casos, no es necesario reinventar la rueda y bien podríamos implementar nuestro compilador para que use LLVM (y así nos beneficiaríamos de todas las optimizaciones y plataformas que soporta) o genere MSIL de .NET o hasta bytecode de Java.
Nuestro compilador, Titan, implementará la generación de código de una forma más sencilla. Estará integrado en el mismo «parser», como es común en compiladores de una sola pasada, de modo que mientras vayamos identificando a los correspondientes elementos sintácticos, iremos escribiendo código ensamblador en el archivo de salida.
16.3 Bucles
Todos los lenguajes estructurados modernos incluyen algún tipo de instrucción repetitiva, como FOR, REPEAT, DO o WHILE.
Pero no es necesario implementar todas estas estructuras repetitivas en un lenguaje. Basta con implementar la estructura WHILE, para poder implementar todas las demás estructuras repetitivas a partir de esta.
Por ejemplo, una instrucción FOR (expresada en un dialecto de BASIC) de la forma:
FOR i=1 TO 100
x = x + 1
NEXTPuede representarse con una estructura WHILE, en la forma:
i = 1
WHILE i < 100
x = x + 1
i = i + 1
WENDUn código que usa DO … WHILE (o REPEAT … UNTIL) de la siguiente forma;
DO
i = i + 1
WHILE i < 100Podemos representarla de la siguiente forma:
WHILE true
i = i + 1
IF i >= 100 THEN break
WENDInclusive, y tal como lo hacía los lenguajes antiguos, solo bastaría instrucciones condicionales y de salto para implementar cualquier tipo de instrucción repetitiva.
16.4 Implementando WHILE
La implementación la haremos de la misma forma que hicimos para el IF, eso es, usando unas macros especiales del MASM32. Para este caso, podemos hacer uso de la macro .WHILE que tiene la sintaxis:
.WHILE <condición>
<sentencias>
.ENDWPor ejemplo, se puede usar esta macro en la siguiente forma:
.WHILE (buffer[bx] != '@')
inc bx
.ENDWLas condiciones soportadas son las mismas que soporta la macro .IF.
Pero hay un detalle: Nuestras expresiones pueden ser más complejas que las que puede soportar la macro .WHILE en una única línea (Como prueba de ello, se puede ver el código de ejemplo que se genera en una condicional, como se describió en la sección 15.7).
Por lo tanto, en Titan implementaremos los bucles WHILE usando las siguiente forma:
.WHILE 1
<código de evaluación de condición>
.IF <condición>
.ELSE
.BREAK
.ENDIF
<cuerpo del WHILE>
.ENDWEn resumen, la idea es incluir un IF dentro del WHILE para determinar si se cumple la condición de permanecer en el bucle. De otra forma, se sale con una instrucción BREAK (implementada con la macro .BREAK del MASM32), que es la forma estructurada de salir de cualquier bucle.
Con esta forma de implementar el WHILE ya no nos preocuparemos de la complejidad de la condición, porque toda la evaluación se hará siempre al inicio del WHILE.
16.5 Modificaciones en nuestro compilador
La primera modificación que haremos será crear un nuevo procedimiento processWhile():
procedure processWhile();
{Procesa una estructura repetitiva}
begin
asmline('.WHILE 1');
NextToken(); //Pasa del "print"
EvaluateIfExpression();
if MsjError<>'' then begin exit; end;
asmline('.ELSE');
asmline(' .BREAK');
asmline('.ENDIF');
TrimSpaces();
if srcToken <> 'do' then begin
MsjError := 'Se esperaba "do"';
exit;
end;
NextToken(); //Toma el "THEN"
//Aquí Procesamos el cuerpo de la condicional.
ProcessBlock(); //Llamada recursiva
if srcToken = 'end' then begin
asmline('.ENDW');
NextToken(); //Toma el "THEN"
end else begin
MsjError := 'Se esperaba "end"';
exit;
end;
end;
Observar que en la sintaxis de nuestro bucle WHILE, estamos exigiendo la palabra reservada DO después de la condición.
La implementación es simple porque estamos reusando muchos de los procedimientos que ya habíamos implementado con anterioridad.
Para finalizar, solo necesitamos incluir el código de detección correspondiente dentro de nuestro procedimiento ProcessBlock():
procedure ProcessBlock;
//Procesa un bloque de código.
begin
while EndOfBlock()<>1 do begin
if srcToken = 'print' then begin
processPrint(0);
if MsjError<>'' then begin break; end;
end else if srcToken = 'println' then begin
processPrint(1);
if MsjError<>'' then begin break; end;
end else if srcToken = 'if' then begin
processIf();
if MsjError<>'' then begin break; end;
end else if srcToken = 'while' then begin
processWhile();
if MsjError<>'' then begin break; end;
end else if srcToktyp = 2 then begin
//Es un identificador, debe ser una asignación
ProcessAssigment();
if MsjError<>'' then begin break; end;
end else begin
MsjError := 'Instrucción desconocida: ' + srcToken;
break;
end;
//Verifica delimitador de instrucción
Capture(';');
if MsjError<>'' then begin exit; end;
end;
end;Con esta modificación ya tenemos soporte para usar estructuras WHILE. Podemos probar con un código sencillo:
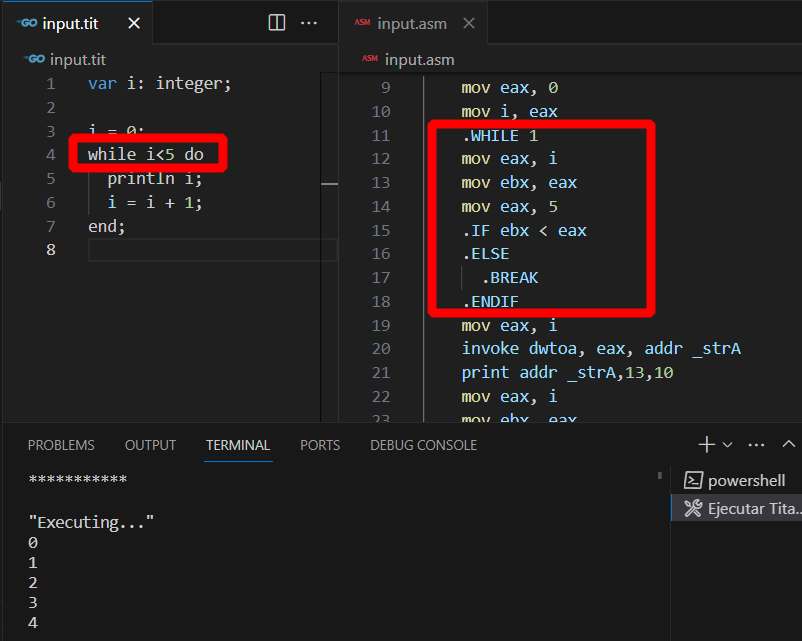
Aunque el código generado es algo más extenso, se puede apreciar que se está siguiendo la estructura prevista que incluye la evaluación de la expresión condicional en la parte inicial del cuerpo del WHILE.
Este sencillo ejemplo solo muestra en pantalla los números del 0 al 4, pero se pueden incluir algoritmos más complejos. Un detalle que no se debe olvidar es asegurar siempre una condición para salir del bucle WHILE. Hay que ser cuidadoso de no crear bucles infinitos, o dejaremos colgados a nuestro programa.
Con esta nueva instrucción WHILE abrimos nuevas posibilidades de implementación para nuestro compilador. El el siguiente capítulo estaré mostrando cómo implementar soporte para procedimientos dentro de nuestro compilador.
Como siempre, se puede acceder al código completo del compilador en mi Github.
![]() ¿Cómo citar este artículo?
¿Cómo citar este artículo?
- En APA: Hinostroza, T. (1 de diciembre de 2023). Crea tu propio compilador – Cap. 16 – Implementación de bucles. Blog de Tito. https://blogdetito.com/2023/12/01/crea-tu-propio-compilador-cap-16-implementacion-de-bucles/
- En IEEE: T. Hinostroza. (2023, diciembre 1). Crea tu propio compilador – Cap. 16 – Implementación de bucles. Blog de Tito. [Online]. Available: https://blogdetito.com/2023/12/01/crea-tu-propio-compilador-cap-16-implementacion-de-bucles/
- En ICONTEC: HINOSTROZA, TIto. Crea tu propio compilador – Cap. 16 – Implementación de bucles [blog]. Blog de Tito. Lima Perú. 1 de diciembre de 2023. Disponible en: https://blogdetito.com/2023/12/01/crea-tu-propio-compilador-cap-16-implementacion-de-bucles/
Hola, disculpa este es el ultimo capitulo de la serie «Crea tu propio compilador»? No consigo encontrar los últimos 4 que se enlistan en el índice del primer capitulo, gracias
Hola.
Aún quedan algunos capítulos pendientes, que he querido completar, pero no he tenido el tiempo necesario. Crear un nuevo artículo de esta serie requiere mucha dedicación y yo solo la avanzo en mi tiempo libre. De momento, estoy dedicado más a otros proyectos personales.