

Contenido de la información
La información genética debería ser todo lo que se necesita saber para crear a un ser vivo. En la actualidad, se ha logrado decodficar la información genética de diversas especies, incluyendo la del ser humano (Proyecto Genoma Humano).
Cuando se decodifica un genoma, lo que se obtiene es un gran libro con un montón de información, que hay que interpretar. En términos informáticos, es como hacer un volcado en binario de un programa ejecutable.
Se desconoce el significado de mucha de la información allí encontrada. Pero, por lo que se sabe hasta ahora, esta información permite generar proteínas y diversos tipos de moléculas de ARN, que son usados por la célula para sus estructuras internas.
En el caso del ser humano, se sabe que su genoma contiene información codificada para:
* La síntesis de proteínas, mediante ARN mensajero (ARNm).
* La síntesis de ARN ribosómico (ARNr).
* La síntesis de ARN de transferencia (ARNt).
* La síntesis de Micro ARN (microARN)
* Otros ARN no codificantes (que no sintetizan proteínas).
La función de cada tipo de ARN es campo de estudio actual. Aún estamos muy lejos de entender por completo, el contenido de información grabado en las cadenas de nucleótidos.
La información genética no es igual en todos los individuos de una misma especie, hay secciones fijas comunes, pero también hay diferencias pequeñas que hacen único a un individuo. Estas pequeñas diferencias son las que dotan a los individuos de rasgos físicos distintivos. En el caso del ser humano pueden determinar el color de la piel, o de los ojos.
De la lista anterior, se podría suponer que el ADN solo sirve para la síntesis de proteínas o ARN no codificante. Pero esto es solo una pequeña fracción de alrededor de 5%. El siguiente diagrama resume la información almacenada en el Genoma Humano.
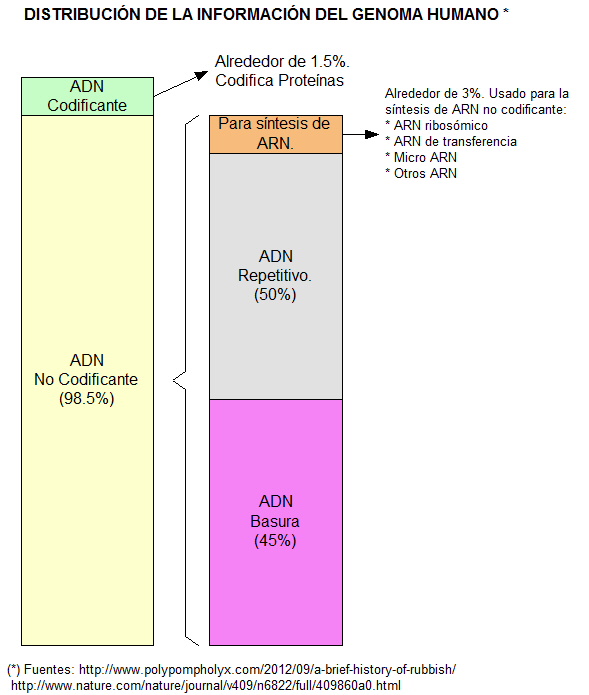
La gran parte del ADN son secuencias repetitivas y lo que se suele llamar ADN basura. Pero nuevos descubrimientos están encontrando ciertas funcionalidades en esta parte del código aparentemente inservible.
En términos informáticos es como encontrar una carpeta de archivos con varios de ellos duplicados o que no han sido usados por mucho tiempo. Mientras se puede observar que solo unos pocos de ellos son leidos frecuentemente.
Codificación de proteínas
Las proteínas son biomoléculas conformadas por cadenas de aminoácidos, y el ADN contiene información para la síntesis de estas proteínas a partir de sus aminoácidos constituyentes.
Cuando los genes almacenan información para la fabricación de proteinas, utiliza unidades de información codificadas en grupos de tres nucleótidos, llamada «codón».
Un codón se cmpone de tres nucleótidos o pares de bases.
3 nucleótidos = 1 codón
El término «codón» no es preciso. Se usa indistintamente para referirse físicamente al grupo de 3 nucleótidos, o a la unidad de información que se codifica en este triplete de nucelótidos.
La información para la fabricación de proteínas se almacena en una secuencia de codones. Cada codón representa un aminoácido, puesto que las proteínas se componen de aminoácidos.
Como el codón tiene 3 nucleótidos, puede tomar hasta 64 valores (equivalente a 6 bits). La siguiente tabla muestra la correspondencia del codón con su respectivo aminoácido:
| 2ª base | |||||
|---|---|---|---|---|---|
| U | C | A | G | ||
| 1ª base | U | UUU Fenilalanina UUC Fenilalanina UUA Leucina UUG Leucina |
UCU Serina UCC Serina UCA Serina UCG Serina |
UAU Tirosina UAC Tirosina UAA Ocre Parada UAG 3Ámbar Parada |
UGU Cysteína UGC Cysteína UGA 2Ópalo Parada UGG Triptófano |
| C | CUU Leucina CUC Leucina CUA Leucina CUG 4Leucina |
CCU Prolina CCC Prolina CCA Prolina CCG Prolina |
CAU Histidina CAC Histidina CAA Glutamina CAG Glutamina |
CGU Arginina CGC Arginina CGA Arginina CGG Arginina |
|
| A | AUU Isoleucina AUC Isoleucina AUA Isoleucina AUG Metionina |
ACU Treonina ACC Treonina ACA Treonina ACG Treonina |
AAU Asparagina AAC Asparagina AAA Lisina AAG Lisina |
AGU Serina AGC Serina AGA Arginina AGG Arginina |
|
| G | GUU Valina GUC Valina GUA Valina GUG Valina |
GCU Alanina GCC Alanina GCA Alanina GCG Alanina |
GAU ácido aspártico GAC ácido aspártico GAA ácido glutámico GAG ácido glutámico |
GGU Glicina GGC Glicina GGA Glicina GGG Glicina |
|
El valor AUG sirve como indicador de Inicio (además de codificar un aminoácido) para una secuencia de aminoácidos en la elaboración de proteinas.
Los valores UAA, UAG y UGA, que no codifican ninguna proteína, son los codones que determinan el fin de la secuencia de traducción de una proteína.
El código es redundante pues existen diversos valores para un mismo aminoácido. Sin embargo, no existe ambiguedad. Se puede notar que en muchos casos el tercer nucleótido de un triplete, no es determinante. Es decir podríamos escribir GUX, para la Valina (donde X representa a cualquier base). Esta característica otorga un factor de seguridad contra errores de copia.
Sorprendentemente, este código es universal en todas las formas de vida, incluyendo animales y plantas. Existen solo pequeñas excepciones en cuanto a los aminoácidos que puede sintetizar un codón, para algunos organismos sencillos. Prácticamente toda la vida en el planeta entiende el mismo código (algo que tal vez deberíamos aprender los humanos), es como si todas las computadoras del mundo utilizarán el mismo lenguaje ensamblador.
A pesar de que pudiera parecer simple, la síntesis de proteínas, a partir de sus aminoácidos es un proceso bastante complejo (aún no comprendido complétamente), sobre todo en células eucariotas, y están apoyados por diversas enzimas.
A grandes rasgos, se extrae del ADN los sectores que codifican proteínas, para pasar esta informacón a una molécula de ARN, llamado ARN mensajero. A este proceso se le llama Transcripción. Posteriormente este ARN mensajero es llevado a los ribosomas, para realizar finalmente las construcción de la proteína usando los aminoácidos codificados en los codones del ARN. A este proceso se le llama Traducción.
Como analogía informática, consideremos el ADN como un archivo de datos enorme (ADN.dat), en donde existen ciertas sectores de información que nos servirán para fabricar proteínas. Parte del trabajo sería ubicar estos sectores de datos (genes), para luego extraer ese fragmento de información (Transcripción), en un pequeño archivo (ARN_mensajero.dat), que luego usaríamos como entrada para un programa al que podríamos llamar «ribosoma.exe», para que este genere una proteína a partir del archivo «ARN_mensajero.dat». A este último proceso se le llamaría «Traducción».
Para un especialista en Genética, explicar la síntesis de proteínas en un par de líneas, equivaldría, a que un expecialista en compiladores, explique usando el mismo par de líneas, cómo una CPU de 8 bits puede ejecutar un programa de alto nivel.
El ADN en cifras
La cantidad de información en el código genético depende de la cantidad de cromosomas y la cantidad de información que almacenen esos cromosomas.
En la siguiente tabla se indica la cantidad de genes para algunas especies de seres vivos:
| Organismo | N.º de genes | Pares de bases |
|---|---|---|
| Plantas | <50000 | <1011 |
| Humanos | 20000 | 3 × 109 |
| Mosca | 12000 | 1,6 × 108 |
| Hongo | 6000 | 1,3 × 107 |
| Bacteria | 500-6000 | 5 × 105 – 107 |
| Mycoplasma genitalium | 500 | 580.000 |
| Virus ADN | 10-300 | 5000 – 800.000 |
| Virus ARN | 1-25 | 1000 – 23.000 |
| Transposones | 1-10 | 2000 – 10.000 |
| Viroides | 0-1 | ~500 |
| Priones | 0 | 0 |
El ADN humano tiene alrededor de tres mil millones de nucleótidos (3200 Mpb). Si cada par de bases representa a 2 bits, podríamos estimar que la cantidad de información que almacena el genoma humano es de 800 Megabytes. Esta es la cantidad de información que podríamos guardar en un CD común.
Hay que considerar que existen porciones grandes de código repetido en el ADN y código sin utilidad aparente. Por lo tanto la cantidad de información almacenada en el genoma podría ser mucho menor.
Contrariamente a lo que se pueda pensar, la cantidad de genes de un animal, no está necesariamente, en proporción a su complejidad. El gusano C. Elegans , tiene casi la misma cantidad de genes que un ser humano (algo de 90%). Algunas plantas, como el arroz, tienen más genes (50000) y pares de bases que el hombre, y hasta una ameba, nos supera enormemente con su genoma.
Al tamaño del genoma de una especie, se le llama su valor C, por ser un valor constante en cada célula del organismo. Al hecho de que la complejidad de un organismo no siempre corresponda con su valor C, se le ha llamado «Paradoja del valor C», y existe amplia literatura sobre este fenómeno.
En términos informáticos, podríamos pensar en que nos encontramos con diversos programas ejecutables, cada cual más complejo que el otro, dentro de una computadora. Pero luego encontramos que algunos de los programas más simples (como aquellas utilidades sencillas de consola) ocupan más espacio en disco que los programas más complejos (con pantallas gráficas y animaciones). Esto desde luego puede pasar considerando como se generan los programas de computadora, pero no es algo que se espere en el ADN de seres que evolucionaron de forma eficiente.
![]() ¿Cómo citar este artículo?
¿Cómo citar este artículo?
- En APA: Hinostroza, T. (5 de febrero de 2015). Lenguaje máquina del ADN – Parte 2. Blog de Tito. https://blogdetito.com/2015/02/05/lenguaje-m-quina-del-adn-parte-2/
- En IEEE: T. Hinostroza. (2015, febrero 5). Lenguaje máquina del ADN – Parte 2. Blog de Tito. [Online]. Available: https://blogdetito.com/2015/02/05/lenguaje-m-quina-del-adn-parte-2/
- En ICONTEC: HINOSTROZA, Tito. Lenguaje máquina del ADN – Parte 2 [blog]. Blog de Tito. Lima Perú. 5 de febrero de 2015. Disponible en: https://blogdetito.com/2015/02/05/lenguaje-m-quina-del-adn-parte-2/
Dejar una contestacion