

5.1 Introducción
Ahora que ya tenemos nuestro ambiente de trabajo preparado y nuestro lenguaje diseñado, vamos a empezar con crear las primeras rutinas de nuestro compilador.
Por un tema de orden y dependencias, nos conviene iniciar con las rutinas del análisis léxico (lexer).
En esta sección empezaremos realizando algunos códigos de prueba como forma de entender el trabajo y la necesidad de un lexer, además de ir familiarizándonos con la escritura de código en Lazarus.
Al final, terminaremos con algunas rutinas que no completan a un analizador léxico pero que nos ayudarán en su construcción final.
5.2 Teoría de Compiladores
Partes de un compilador
A estas alturas del proyecto, y antes de iniciar el desarrollo del código fuente del compilador, deberíamos tener claro, cuáles son las partes de las que se compone un compilador.
Los compiladores pueden hacerse de tantas formas como se pueden hacer las tortas de chocolate. Eso es lo bueno y lo malo de hacer compiladores. No existe un «Comité Internacional Regulador de las formas en que se hacen los Compiladores» ni nada parecido, como no existe un «Comité Internacional Regulador de las formas en que se hacen las Tortas de Chocolates». El conocimiento actual que se tiene sobre el diseño de compiladores, es producto de la teoría y práctica desarrollada a lo largo de los últimos años, pero es un tema abierto a la investigación.
Así, que por favor, dejar de preguntar ¿Cómo se hacen los compiladores? Una mejor pregunta sería, ¿Podría explicarme alguna forma en que se hacen los compiladores?
Por suerte, la mayoría de compiladores presentan partes (también llamadas «fases») más o menos definidas. El siguiente esquema representa a las fases de un compilador típico:
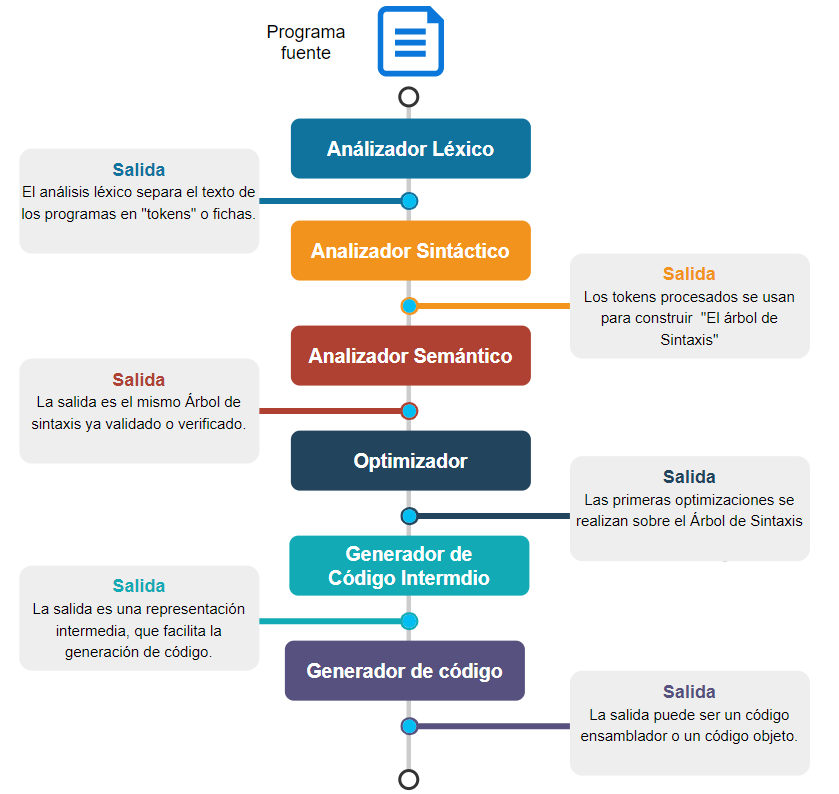
Esta no es una estructura universal. Existen diversas variaciones a esta estructura. Nosotros mismos con nuestro compilador estamos rompiendo este esquema.
Analizador léxico.- También conocido como «lexer». Es quien identifica y extrae los llamados «tokens», que son los elementos mínimos de caracteres con significado coherente para un lenguaje de programación.
Analizador sintáctico.- También conocido como «parser». Es quien procesa los tokens de acuerdo a las reglas de la gramática del lenguaje de programación (Como dónde es permitido un identificador). Por lo general su resultado termina en lo que se llama «Árbol de sintaxis»
Analizador semántico.- Aunque menos conocido e identificado, este analizador realiza una comprobación de mayor nivel al código fuente, como por ejemplo, si un tipo de datos es válido en la posición donde se encuentra. Trabaja sobre el árbol de sintaxis que se genera en el análisis sintáctico y puede agregarle información adicional.
Árbol de sintaxis.- Puede haber uno o varios. Es una estructura ramificada que representa al código fuente en cuanto a estructura. Los nodos del árbol pueden representar a funciones o declaraciones. Se usa para realizar el análisis semántico y para la generación de código.
Generador de código intermedio.- Muchos compiladores incluyen este módulo, cuyo principal objetivo es realizar al primera etapa en la generación de código. Se suele usar un código intermedio, para simplificar la generación de código y para facilitar la creación de nuevos generadores de código.
Generador de código.- Es el módulo que crea el código destino Lo ideal es que el código destino sea binario o ejecutable, pero la mayoría de compiladores solo crean código objeto o, inclusive, solo código ensamblador (como vamos a hacer nosotros).
Optimizador de código.- La optimización de código se puede realizar en diversos niveles, como en la etapa previa a la generación de código o en el archivo objeto generado. La idea es obtener un código simplificado, óptimo y/o rápido. Para ellos existen diversas reglas y técnicas aplicables.
Cada una de esta fase puede llegar a ser muy compleja y hay especialista que constantemente están haciendo investigaciones y aportes. Las técnicas para crear compiladores no están escrito en un libro sagrado.
Al hablar de compiladores se suele usar el concepto «pasada» que podría confundirse con «fase». Una pasada sin embargo es una exploración completa que realiza el compilador y que puede involucrar varias fases. Este concepto se tratará con más detalle en el Capítulo 9.
5.3 Cómo escribiremos nuestro compilador
En este artículo, iniciaremos la escritura de código, y como ya hemos mencionado, vamos a tener en consideración algunas reglas básicas al momento de escribir las rutinas del compilador. Estás son:
- Usaremos el lenguaje Pascal en sus capacidades básicas. No se usarán las capacidades de Object Pascal.
- Solo usaremos Pascal como lenguaje imperativo y tipado.
- Solo usaremos dos tipos de datos: Integer y String.
- Solo usaremos condicionales simples IF .. THEN … ELSE.
- Solo usaremos los bucles WHILE. No usaremos REPEAT o FOR.
- No se usarán procedimientos anidados dentro de otro procedimiento.
- No se usarán librerías de terceros. Todo el compilador se implementará desde cero con las funciones nativas del lenguaje manejo de cadenas y números.
- No se usarán punteros.
- El tipo «string» de Pascal que utilizaremos, estará restringido (por convención) a un tamaño máximo de 255 caracteres.
- Las funciones de manejo de archivos deben ser también las nativas que implementa el lenguaje.
- Las funciones y procedimientos pueden recibir parámetros pero solo por valor, no por referencia [1. En realidad usaremos la referencia para los parámetros cadena, pero solo para lectura].
- Al no tener tipos booleanos, se usarán valores enteros para emularlos, tomando en consideración que el valor 0 representa a FALSE.
- Al no tener tipos «char» se usarán valores enteros.
- Se usarán expresiones simples de dos o tres operandos.
Se puede notar que existen restricciones fuertes en cuanto a lo que podemos (y lo que no podemos) usar del lenguaje. Esto constituye un desafío adicional a la hora de escribir el compilador, pero nos servirá para:
- En el futuro, poder traducir el compilador del Pascal al propio lenguaje del compilador.
- Facilitar el entendimiento y la explicación del código fuente del compilador.
Habiendo dejado en claro las restricciones al momento de escribir el código, pasamos entonces al primer módulo del compilador.
5.4 Nuestro Analizador Léxico
En comparación con los compiladores profesionales, nuestro analizador léxico parecerá un juego de niños, pero no por eso dejará de ser funcional.
Para entender mejor los analizadores léxicos, sugiero leer mi artículo Jugando con palabras – Analizadores lexicos
Nuestro lexer será simplemente un conjunto de procedimientos y funciones que nos permitirán reconocer los diversos tipos de tokens con los que trabajaremos en nuestro lenguaje de programación.
Por simplicidad solo definiremos los siguientes tipos de tokens:
- Saltos de línea
- Espacios.
- Identificadores
- Literales numéricos
- Literales cadena
- Comentarios
- Operadores
- Fin de archivo
- Tokens desconocidos
Con estos tipos de tokens nos será suficiente para representar a todos los elementos de nuestro lenguaje. Se pueden crear menos o más tipos, dependiendo de las necesidades del lenguaje que vayamos a implementar. Crear más o menos tipos que los necesarios solo agregará código o lógica adicional a nuestro compilador.
Los espacios son los que corresponden al carácter #32 (del código ASCII), pero también se incluirá a las tabulaciones #9.
Los saltos de línea son los delimitadores de línea, y en Windows se representan por dos caracteres: #10 y #13.
Los identificadores se definieron en el artículo anterior, cuando creamos el lenguaje.
Los literales cadena son caracteres delimitados por comillas dobles, como «Hola» o «esto es una cadena».
Los literales numéricos son caracteres numéricos como: 123 o 002. De momento no consideraremos números con decimales o en coma flotante.
Todos los otros tokens serán considerados como desconocidos, pero también tendrán un tipo. En este grupo caerán los símbolos como «;» o «:».
Nuestro lexer se construirá con un diseño lógico al que podríamos decir «por capas», donde las capas son un conjunto de subrutinas (procedimientos o funciones) que trabajan de manera relacionada usando las rutinas de las capas inferiores y ofreciendo sus funciones a la capa superior.
En nuestro caso podremos diferenciar hasta 3 capas, en la estructura del lexer:
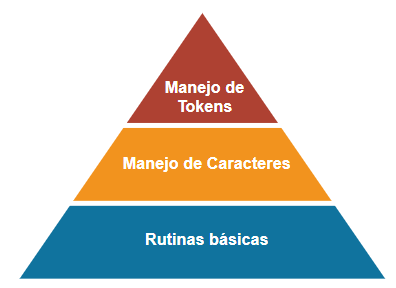
La capa más alta, la de Manejo de Tokens, constituye la capa de mayor nivel de abstracción y trabajará sobre las capas inferiores.
Empezaremos escribiendo las rutinas básicas y de manejo de carácteres, pero antes, como un entrenamiento, recordaremos la exploración de un archivo línea por línea.
5.5 Primer acercamiento: Exploración línea por línea
En el segundo artículo habíamos dejado el entorno de Lazarus listo para empezar a trabajar. Ahora vamos a continuar creando un archivo que será nuestro primer programa en nuestro lenguaje Titan.
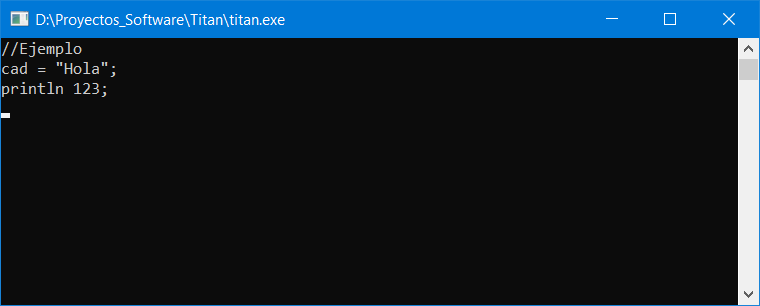
Recordando la configuración de archivos que dejamos en nuestra carpeta «D:\Proyectos_Software\Titan\», habíamos creado un archivo vacío llamado «input.tit». Ahora, para las pruebas, le pondremos el siguiente contenido:
//Ejemplo
cad = "Hola";
println 123;Si abrimos este archivo en nuestra configuración de VSCode, tendríamos esto:
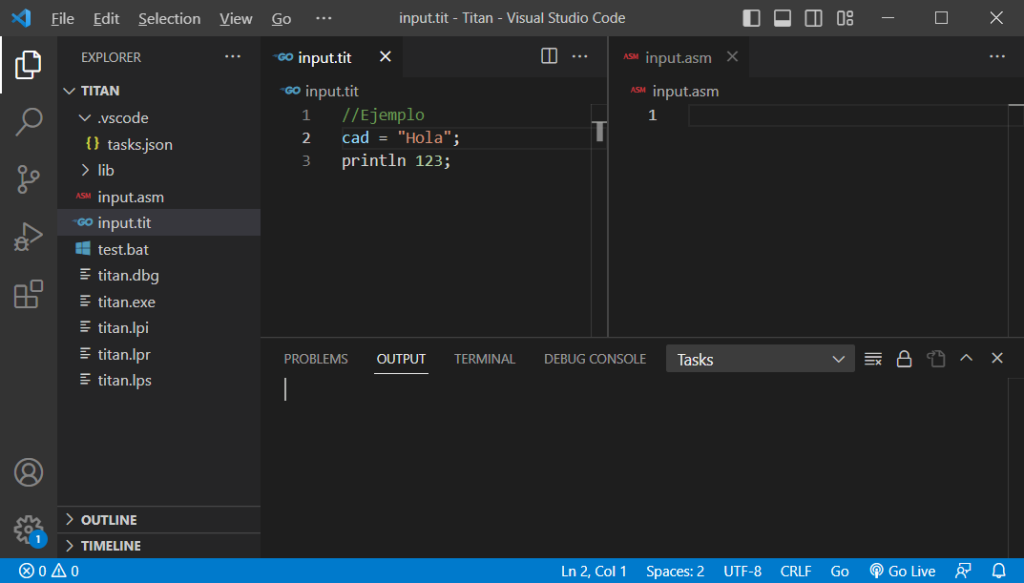
Este archivo no es un código coherente, sino simplemente una buena muestra para probar nuestro analizador léxico, porque contiene los elementos sintácticos que vamos a usar.
Este archivo lo debemos poner en la la misma carpeta en donde tenemos nuestro proyecto de Lazarus, de modo que en nuestra carpeta de trabajo tenemos ya varios archivos:
Como nuestra intención es leer los tokens de un archivo fuente, empezaremos con la rutina para leer líneas de un archivo de texto. Abrimos el proyecto titan.lpi con Lazarus y escribimos el siguiente código:
{Proyecto de un compilador con implementación mínima.}
program titan;
var
inFile : Text; //Archivo de entrada
srcLine : string; //Línea leída actualmente
begin
AssignFile(inFile, 'input.tit');
Reset(inFile);
while not eof(inFile) do begin
readln(inFile, srcLine);
writeln(srcLine);
end;
Close(inFile);
ReadLn;
end.
Este es el esquema típico de un programa para lectura de archivos en Pascal. Si lo ejecutamos veremos el contenido del archivo «input.tit» en la consola.
5.6 Rutinas básicas de un lexer
La exploración línea por línea está lejos de ser un analizador léxico, porque solo extrae líneas y las líneas no se consideran tokens en nuestra definición. Sin embargo, este código será la base de nuestro analizador léxico, que funcionará también leyendo líneas del archivo fuente.
Nuestro lexer se alimentará de las líneas de texto de un archivo, así que por simplicidad (ya que no podemos usar características avanzadas del lenguaje) usaremos una variable cadena para almacenar cada línea que vayamos leyendo del archivo. A esta variable la llamaremos «srcLine»:
var srcLine : string; //Línea leída actualmente
Ahora esta línea debe ser explorada carácter por carácter, así que necesitaremos acceder a ella como arreglo y necesitaremos también un índice, o puntero, para ir leyendo cada carácter de la «srcLine». A ese índice lo llamaremos «idxLine»:
var idxLine : integer;
También necesitaremos dos variables más para manejar el archivo de entrada (código fuente) y el archivo de salida (archivo en ensamblador) que generará nuestro compilador:
var inFile : Text; //Archivo de entrada
var outFile : Text; //Archivo de salidaAhora teniendo ya estas variables, podemos implementar algunas funciones básicas de lo que será nuestro «lexer»:
function next_is_EOL(): integer;
//Devuelve 1 si el siguiente token corresponde a un Fin de Línea (EOL).
begin
if idxLine > length(srcLine) then begin
exit(1);
end else begin
exit(0);
end;
end;
function next_is_EOF(): integer;
//Devuelve 1 si el siguiente token corresponde a un Fin de Archivo (EOF).
begin
if eof(inFile) then begin
//Ya no hay más líneas pero aún hay que asegurarse de que estamos al
//final de la línea anterior.
if next_is_EOL()=1 then begin exit(1)
end else begin exit(0); end;
end else begin
exit(0);
end;
end;
Estas funciones verifican de los límites del archivo de entrada «input.tit».
Esto es importante porque conforme vayamos haciendo la exploración, se puede dar el caso en que hayamos llegado al final del archivo, y en ese momento ya no tiene sentido seguir explorando. La verificación de fin de línea (next_is_EOL) es usada para saber cuando debemos leer la siguiente línea, aunque esto solo se ve a niveles bajos del «lexer» (funciones más básicas) porque a niveles más altos, el cambio de línea es algo que se realizará de forma transparente.
Notar que las funciones next_is_EOL y next_is_EOF deberían devolver valores booleanos, pero aquí están devolviendo números, para cumplir con las restricciones del lenguaje que podemos usar. Una de ellas es, precisamente, que solo podemos usar datos de tipo «integer» y «string», aunque podemos usar también enteros sin signo o de menor capacidad, sin perder la esencia de la restricción.
La lógica de estas funciones es simple así que no creo que el lector tenga problemas en la interpretación.
Notar que las llamada a la función next_is_EOL, se hace de la forma «next_is_EOL()» incluyendo los paréntesis y no de la forma «next_is_EOL». Esto es así porque queremos facilitar la migración futura del código fuente de nuestro compilador al lenguaje Titan, en donde son obligatorios los paréntesis para llamar a procedimientos o funciones.
Otra de las rutinas que necesitamos es la que permite el desplazamiento a través del archivo de entrada, leyendo línea por línea, que es la forma natural en que se leen los archivos de texto.
procedure NextLine();
//Pasa a la siguiente línea del archivo de entrada
begin
if eof(inFile) then begin exit; end;
readln(inFile, srcLine); //Lee nueva línea
idxLine:=1; //Apunta a primer caracter
end;
La lectura línea por línea es rápida y sencilla pero no corresponde a la forma en que se explora un programa (carácter por carácter o token por token). Una alternativa a la lectura línea por línea sería leer el archivo de entrada carácter por carácter, y eso nos facilitaría la implementación del lexer, pero sería carga innecesaria en el rendimiento.
Poner atención en la forma en que se pasa a una nueva línea, reiniciando el índice «idxLine» a 1, para empezar a explorar desde el primer carácter.
Una mejora que podríamos hacer para este código es incluir un contador de líneas procesadas para poder saber en qué línea se produce un error. Para ello debemos agregar una variable, a la que llamaremos «srcRow» y nuestro procedimiento NextLine quedaría:
procedure NextLine(); //Pasa a la siguiente línea del archivo de entrada begin if eof(inFile) then begin exit; end; readln(inFile, srcLine); //Lee nueva línea inc(srcRow); idxLine:=1; //Apunta a primer carácter end;
Hay algunos detalles que debemos notar en la forma en que estamos escribiendo nuestros códigos. El primero es que todas las declaraciones de procedimientos o funciones incluyen los paréntesis () después del nombre, aún cuando el procedimiento no incluya parámetros. Normalmente en Pascal no es necesario incluir los paréntesis si no vamos a declarar parámetros, pero nosotros escribiremos los paréntesis para facilitar la traducción del código fuente del compilador al lenguaje Titan, en donde sí son obligatorios los paréntesis en la declaración de procedimientos y funciones.
Otro detalle es que todas las condicionales se están escribiendo en la forma «IF … THEN BEGIN … END;» ,a pesar de que en Pascal no es necesario usar BEGIN … END cuando solo haya una instrucción dentro del bloque. El motivo es el mismo. Escribimos nuestro código en esta forma para facilitar la posterior traducción de este compilador al lenguaje Titan.
Otro detalle que no se ve en este código pero que si se notará
5.7 Exploración de caracteres
Las rutinas anteriores son solo la base sobre la que construiremos las verdaderas rutinas del lexer. Pero aún con estas rutinas, todavía no tenemos la capacidad de identificar y extraer tokens. Aún tenemos que escribir rutinas de mayor nivel.
Las rutinas que suelen ser «un clásico» entre los lexers son las llamadas NextChar() y ReadChar() cuya función se puede deducir del mismo nombre.
Empezaremos definiendo estas funciones, del tipo «carácter por carácter». Estas rutinas nos servirán luego para implementar la rutina que explora token por token. Nuestras funciones en cuestión serán NextChar() y ReadChar():
procedure NextChar();
{Incrementa "idxLine". Pasa al siguiente carácter.}
begin
idxLine := idxLine + 1; //Pasa al siguiente carácter
end;
procedure ReadChar();
{Lee el carácter actual y actualiza "srcChar".}
begin
srcChar := ord(srcLine[idxLine]);
end;
NextChar() solo se va moviendo carácter por carácter sobre la línea actualmente leída. ReadChar() lee el carácter actual, al que apunta «idxLine», en la variable global «srcChar», que es numérica. También se pudo retornar como resultado de la función, sin problemas, pero aquí se está tratando de usar la forma minimalista de trabajar usando variables globales [2. Aunque no es una práctica recomendable el uso de variables globales, por los posibles efectos negativos que puede ocasionar.]. De cualquier forma, el cambio es trivial.
Estas dos rutinas funcionan casi siempre a la par: Primero se llama a NextChar() para moverse un carácter en el texto de entrada y luego se llama a ReadChar() para obtener el carácter actual en «srcChar».
Es notoria la simplicidad del código de estas rutinas, pero hay unos detalles que podemos mejorar. Por ejemplo, si siempre vamos a estar llamando al par NextChar() – ReadChar(), conviene juntar ambas rutinas en una sola, que además actualice «srcChar». Por ello juntaremos ambas funciones en una sola que nos ofrezca el trabajo de ambas. El código de la rutina sería:
procedure NextChar();
//Incrementa "idxLine". Pasa al siguiente caracter.
begin
idxLine := idxLine + 1; //Pasa al siguiente caracter
//Actualiza "srcChar"
if next_is_EOL()=1 then begin //No hay más caracteres
srcChar := 0;
end else begin
srcChar := ord(srcLine[idxLine]);
end;
end;Hay que notar que solo trabajan en la línea «srcLine» y que se necesita hacer frecuentes verificaciones con next_is_EOL() para luego cambiar a la siguiente línea con NextLine(), de otra forma al intentar explorar más allá de «srcLine», se generaría un error en tiempo de ejecución.
Sería un buen ejercicio, y también recomendable, proponer mejoras al código NextChar(), pero tal como está nos puede servir bien para nuestro trabajo.
Con estas rutinas listas ya podríamos crear un bucle para ir explorando caracteres de una línea y tendría la forma:
while next_is_EOL()=0 do begin
NextChar; //Toma caracter
//Hace algo con "scrChar"
end;
Notar la forma en que se compara el valor booleano (entero) que devuelve next_is_EOL().
Si ahora juntamos todas las rutinas mostradas, tendríamos algo así:
{Proyecto de un compilador con implementación mínima para ser autocontenido.}
program titan;
var
//Manejo de código fuente
inFile : Text; //Archivo de entrada
outFile : Text; //Archivo de salida
idxLine : integer;
srcLine : string; //Línea leída actualmente
srcRow : integer; //Número de línea áctual
srcChar : byte; //Carácter leído actualmente
function next_is_EOL(): integer;
//Devuelve 1 si el siguiente token corresponde a un Fin de Línea (EOL).
begin
if idxLine > length(srcLine) then begin
exit(1);
end else begin
exit(0);
end;
end;
function next_is_EOF(): integer;
//Devuelve 1 si el siguiente token corresponde a un Fin de Archivo (EOF).
begin
if eof(inFile) then begin
//Ya no hay más líneas pero aún hay que asegurarse de que estamos al
//final de la línea anterior.
if next_is_EOL()=1 then begin exit(1)
end else begin exit(0); end;
end else begin
exit(0);
end;
end;
procedure NextLine();
//Pasa a la siguiente línea del archivo de entrada
begin
if eof(inFile) then begin exit; end;
readln(inFile, srcLine); //Lee nueva línea
inc(srcRow);
idxLine:=1; //Apunta a primer caracter
end;
procedure NextChar();
//Incrementa "idxLine". Pasa al siguiente caracter.
begin
idxLine := idxLine + 1; //Pasa al siguiente caracter
//Actualiza "srcChar"
if next_is_EOL()=1 then begin //No hay más caracteres
srcChar := 0;
end else begin
srcChar := ord(srcLine[idxLine]);
end;
end;
begin
//Abre archivo de entrada
AssignFile(inFile, 'input.tit');
Reset(inFile);
NextLine(); //Lee primera línea en "srcLine"s
idxLine := 0; //Para empezar a leer en el caracter 1
while next_is_EOL()=0 do begin
NextChar(); //Toma caracter
write(chr(srcChar)); //Hace algo con "scrChar"
end;
Close(inFile);
ReadLn;
end.
Excepto por el cuerpo principal del programa, todas las rutinas anteriores nos servirán para la construcción del lexer.
Si ejecutamos el programa, este nos mostrará carácter por carácter, el contenido de la primera línea del archivo de entrada, como se aprecia en la siguiente figura:
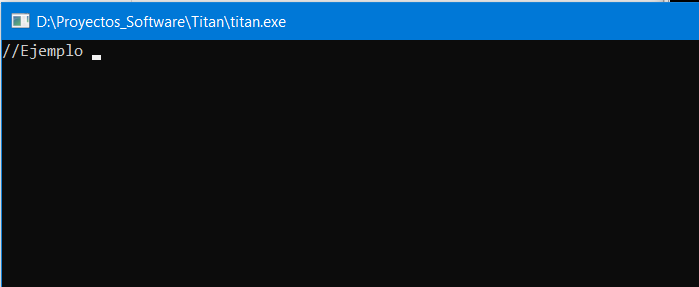
Aunque este programa no es un lexer aún, porque no extrae tokens sino caracteres, conviene estudiarlo (y ejecutarlo) para seguir adelante con el desarrollo con buen entendimiento.
En el siguiente artículo terminaremos de implementar el analizador léxico, implementando, finalmente, la rutina con capacidad de extraer tokens de todas las líneas del archivo de entrada de una forma cómoda y transparente.
![]() ¿Cómo citar este artículo?
¿Cómo citar este artículo?
- En APA: Hinostroza, T. (13 de enero de 2019). Crea tu propio compilador – Cap. 5 – Creando un analizador léxico. Blog de Tito. https://blogdetito.com/2019/01/13/crea-tu-propio-compilador-parte5/
- En IEEE: T. Hinostroza. (2019, enero 13). Crea tu propio compilador – Cap. 5 – Creando un analizador léxico. Blog de Tito. [Online]. Available: https://blogdetito.com/2019/01/13/crea-tu-propio-compilador-parte5/
- En ICONTEC: HINOSTROZA, Tito. Crea tu propio compilador – Cap. 5 – Creando un analizador léxico [blog]. Blog de Tito. Lima Perú. 13 de enero de 2019. Disponible en: https://blogdetito.com/2019/01/13/crea-tu-propio-compilador-parte5/
Dejar una contestacion