

6.1 Introducción
En el capítulo anterior empezamos a construir nuestro analizador léxico, creando las rutinas básicas y las que manejan la extracción de caracteres uno a uno (Ver Figura 5.2).
En este capítulo terminaremos de escribir el código de nuestro lexer, creando la rutina que realiza la exploración token por token y las rutinas asociadas.
A pesar de la simplicidad de nuestro lexer, este se parecerá mucho a las implementaciones de muchos programas similares, excepto tal vez, porque nosotros nos estamos restringiendo a usar las características más básicas del lenguaje Pascal.
Una gran diferencia de nuestro lexer, con respecto a las implementaciones actuales, es que los analizadores léxicos actuales no se suelen escribir a mano, sino que usan generadores como LEX, que crean el código fuente de un lexer (generalmente en C) a partir de una definición del lenguaje.
6.2 Teoría de Compiladores
Lexer y Parser
Como ya vimos, los analizadores léxicos nos permiten extraer tokens. Un analizador sintáctico (parser), sin embargo, extrae elementos sintácticos, del código fuente.
¿Qué son elementos sintácticos?
Se podría decir que son los mismos tokens, pero con una interpretación distinta. Consideremos un ejemplo. La palabra «mi_variable» es considerada por el lexer, como un simple identificador (variable, constante, tipo, …). Para el parser, sin embargo, puede tratarse del nombre de una variable. Eso implica que el «parser» tienen un conocimiento, a mayor nivel, del código fuente.
¿Qué que hacen los analizadores sintácticos?
Los analizadores léxicos solo generan tokens, y estos tokens son usados por el analizador sintáctico para que realice su trabajo, que por lo general, consiste en llenar una (o más de una) estructura llamada «El árbol de sintaxis», que es luego usada para la generación de código.
Un analizador sintáctico puede también usar lo que se llama «La tabla de símbolos». Esta estructura sirve para facilitar el reconocimiento de ciertos elementos sintácticos, del código fuente. Un compilador de C, por ejemplo, necesita de forma obligatoria una tabla de símbolos. Un compilador de Pascal, sin embargo, puede trabajar sin una.
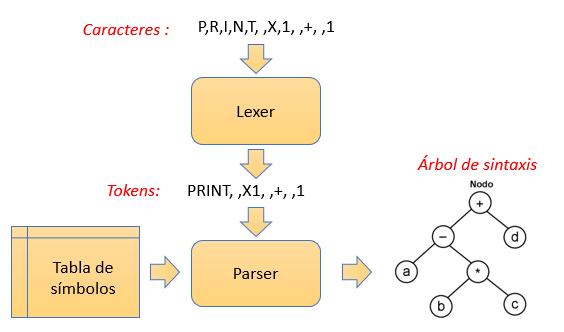
El analizador sintáctico se maneja en base a reglas de una gramática conocida como «Gramática libre de contexto» (context-free grammar) , a diferencia de los analizadores léxicos que se manejan en al ámbito de las gramáticas regulares, usando terminología de la jerarquía de Chomsky.
Existe amplia literatura sobre el tema de las gramáticas que conviene leer un poco, si se desea profundizar en la teoría de los lenguajes de los compiladores.
¿Son realmente diferentes los lexer de los parser?
El analizador léxico y el sintáctico son dos módulos diferentes de un compilador con funciones diferentes, pero muchas veces estas diferencias no están bien separadas.
Pueden existir lenguajes con tokens bastante sencillos, de modo que no requieran un analizador sintáctico.
Hay toda una teoría (en realidad, más de una) detrás de este tema, pero siempre hay opiniones diversas y hasta contradictorias.
Como nosotros no pretendemos ser especialistas en el tema, solo nos bastará con asumir que se tratan de módulos distintos. La experiencia nos dirá luego cuáles son las diferencias.
Sin embargo, uno de los métodos que nos sirven para detectar la diferencia de un analizador léxico con un analizador sintáctico, es que: Los parser suelen manejar recursividad, los lexer no. Siempre habrá excepciones, de acuerdo a la implementación, así que esto es solo una guía.
Los conceptos teóricos pueden parecer intimidantes pero constituye la base de un buen desarrollador de compiladores.
6.3 El diseño de nuestro lexer
Volviendo al diseño del analizador léxico de nuestro compilador Titan, y antes de implementar la rutina de exploración de tokens, conviene diseñar la forma en que haremos la exploración del texto de entrada.
El diseño que propongo aquí se basa en el manejo de dos índices al texto de entrada, que en nuestro caso será siempre la línea actual. Estos índices se irán incrementando con cada token explorado. La siguiente figura diagrama esta forma de trabajo:
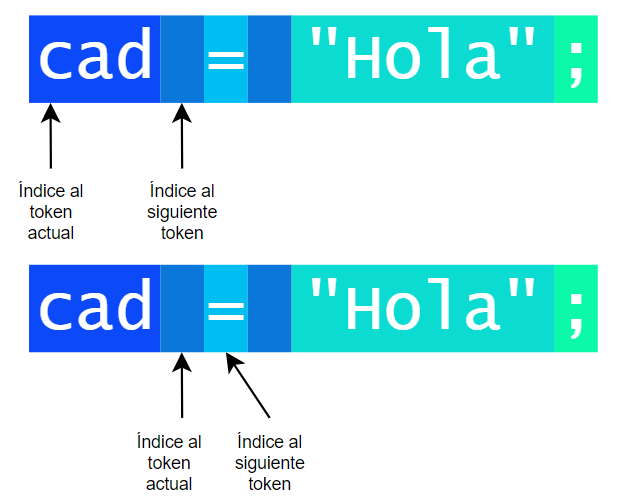
El primer índice o puntero nos indicará dónde empieza el token actual, el mismo que se extenderá hasta antes del inicio del siguiente índice. Con cada llamada a la función de exploración de tokens, a la que llamaremos NextToken(), los índices se moverán a la posición del siguiente token.
Aunque existen diversas versiones de lexer, he elegido este porque tiene la ventaja de poder leer fácilmente el carácter siguiente al token actual, que es bastante útil en algunos casos.
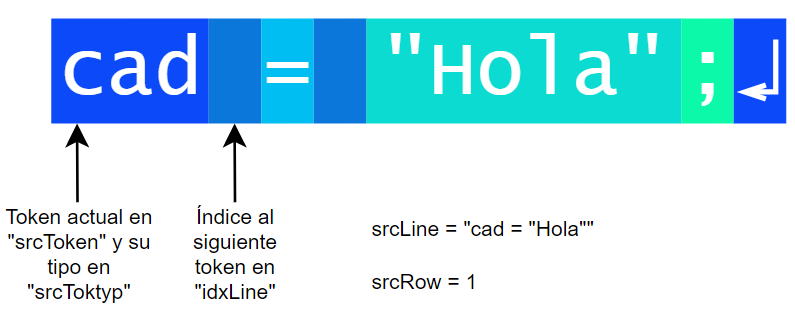
El índice al siguiente token será la misma variable «idxLine» que ya habíamos creado y usado en el capítulo anterior.
Por simplificación, y porque no necesitaremos realmente leer el índice al token actual, lo que haremos en nuestro lexer será usar un par de variables de estado con información sobre el token actual y prescindir del índice al token actual. Estas variables de estado serán:
var srcToken : string; // Token actual
var srcToktyp: integer; // Tipo de token actualEsta es toda la información que necesitaremos sobre el token actual y que es más importante que el índice. De todas formas, si necesitamos leer el índice al token actual, siempre podremos guardar el valor del «Índice al siguiente token» antes de llamar a nuestra función NextToken().
La variable «srcToken» servirá para guardar el token actual, el último que hemos identificado. Lo mantenemos en una variables para poder hacer comparaciones rápidas.
La variable «srcToktyp» es un número que nos servirá como identificador del tipo de token que tenemos en «srcToken», y tendrá la siguiente interpretación:
// 0-> Fin de línea
// 1-> Espacio
// 2-> Identificador: "var1", "VARIABLE"
// 3-> Literal numérico: 123, -1
// 4-> Literal cadena: "Hola", "hey"
// 5-> Comentario
// 6-> Operador
// 9-> Desconocido
//10-> Fin de archivoEsta clasificación obedece a la que habíamos planteado para nuestro lenguaje. Es decir, que identificaremos al token mediante el valor de una variable numérica. Esto es común en la mayoría de analizadores léxicos aunque se prefiere usar tipos enumerados, en lugar de simples números, pero ya sabemos que aquí nos hemos impuesto restricciones en el lenguaje.
6.4 Identificación de caracteres
Como en el código fuente de nuestro compilador no podremos usar condiciones complejas de varias expresiones como «(srcChar>’A’ AND srcChar< ord(‘Z’)) OR (srcChar>’a’ AND srcChar< ord(‘z’))», nos ayudaremos de funciones que nos ayuden a simplificar esas expresiones.
Empezamos creando las funciones de identificaciones de mayúsculas, minúsculas y números:
function IsAlphaUp(): integer;
//Indica si el caracter en "srcChar" es alfabético mayúscula.
begin
if srcChar>=ord('A') then begin
if srcChar<=ord('Z') then begin
exit(1);
end else begin
exit(0);
end;
end else begin
exit(0);
end;
end;
function IsAlphaDown(): integer;
//Indica si el caracter en "srcChar" es alfabético minúscula.
begin
if srcChar=ord('_') then begin exit(1); end;
if srcChar>=ord('a') then begin
if srcChar<=ord('z') then begin
exit(1);
end else begin
exit(0);
end;
end else begin
exit(0);
end;
end;
function IsNumeric(): integer;
//Indica si el caracter en "srcChar" es numérico.
begin
if srcChar>=ord('0') then begin
if srcChar<=ord('9') then begin
exit(1);
end else begin
exit(0);
end;
end else begin
exit(0);
end;
end;
Notar que, debido a las restricciones que nos hemos impuestos, estamos haciendo uso de una variable numérica (srcChar) en lugar de una de tipo «char», lo que facilitaría el código.
Notar también que estas rutinas no serían necesarias si pudiéramos usar conjuntos (una característica útil en el lenguaje Pascal) en nuestro código, pero como estamos restringiendo las funcionalidades del lenguaje, no nos queda otra que implementar el reconocimiento de caracteres de forma «manual».
Un detalle que puede parecer extraño es que se está incluyendo el carácter «_» como si fuera parte de los caracteres en minúscula, dentro de la función IsAlphaDown(). La razón es simplemente por comodidad. Se pudo haber incluido en IsAlphaUp(), en ExtractIdentifier() o en su propia función.
Estas funciones están aún por debajo de la tarea de extraer tokens, solo identifican caracteres, así que debemos crear otras funciones de mayor nivel que nos acerquen más a los tokens.
El enfoque que planteo aquí, es usar una rutina para cada tipo de token que se vaya a procesar, en lugar de usar una sola rutina para identificar a todos los tipos de tokens. De esta forma se simplifica el código de identificación.
Las siguientes funciones utilizan las rutinas vistas en el artículo anterior y las rutinas de identificación que hemos mostrado aquí para explorar líneas e ir extrayendo caracteres (incrementando el índice «idxLine») de acuerdo al tipo de elemento que manejen:
procedure ExtractIdentifier();
var
IsToken: integer; //Variable temporal
begin
srcToken := '';
srcToktyp := 2;
IsToken := 1;
while IsToken=1 do begin
srcToken := srcToken + chr(srcChar); //Acumula
NextChar(); //Pasa al siguiente
if next_is_EOL()=1 then begin //No hay más caracteres
exit;
end;
IsToken := IsAlphaUp() or IsAlphaDown();
IsToken := IsToken or IsNumeric();
end;
end;
procedure ExtractSpace();
var
IsToken: integer; //Variable temporal
begin
srcToken := '';
srcToktyp := 1;
IsToken := 1;
while IsToken=1 do begin
srcToken := srcToken + chr(srcChar); //Acumula
NextChar(); //Pasa al siguiente
if next_is_EOL()=1 then begin //No hay más caracteres
exit;
end;
if srcChar = ord(' ') then begin
IsToken := 1;
end else if srcChar = 9 then begin
IsToken := 1;
end else begin
IsToken := 0;
end;
end;
end;
procedure ExtractNumber();
var
IsToken: integer; //Variable temporal
begin
srcToken := '';
srcToktyp := 3;
IsToken := 1;
while IsToken=1 do begin
srcToken := srcToken + chr(srcChar); //Acumula
NextChar(); //Pasa al siguiente
if next_is_EOL()=1 then begin //No hay más caracteres
exit;
end;
IsToken := IsNumeric();
end;
end;
procedure ExtractString();
var
IsToken: integer; //Variable temporal
begin
srcToken := '';
srcToktyp := 4;
IsToken := 1;
while IsToken=1 do begin
srcToken := srcToken + chr(srcChar); //Acumula
NextChar(); //Pasa al siguiente
if next_is_EOL()=1 then begin //No hay más caracteres
exit;
end;
if srcChar <> ord('"') then begin
IsToken := 1; //True
end else begin
IsToken := 0; //False
end;
end;
NextChar(); //Toma la comilla final
srcToken := srcToken + '"'; //Acumula
end;
procedure ExtractComment();
begin
srcToken := '';
srcToktyp := 5;
while next_is_EOL()=0 do begin
srcToken := srcToken + chr(srcChar); //Acumula
NextChar(); //Toma caracter
end;
end;
Observar que las rutinas de exploración de caracteres se parece al mismo esquema que vimos en el artículo anterior, pero ahora hemos agregado condicionales adicionales para filtrar los caracteres correspondientes.
Algunas partes del código tienen apariencia extraña porque se están simplificando las expresiones para cumplir con la limitación de usar expresiones sencillas.
Si bien estas rutinas se han definido de forma que se adapten a nuestro lenguaje, el lector bien puede hacer las modificaciones que considere necesario para adaptarlas a su lenguaje, si tiene diferencias sustanciales (y no solo identificadores diferentes) al que yo he propuesto.
Todas las rutinas cumplen con dejar el resultado en «srcToken» y actualizan «srcToktyp». Pero estas rutinas no identifican al token en sí, sino que requieren que se haga una identificación previa del carácter inicial (que se hace antes de llamar a estas rutinas) para ir revisando los caracteres siguientes e ir discriminando si pertenecen o no al tipo de token que manejan. Se podría decir que estas funciones procesan los «caracteres siguientes».
Lo que nos faltaría es una rutina, que pueda hacer la primera identificación, en base al primer carácter (o dos primeros), qué tipo de token se nos presenta. Esta identificación es simple, porque por ejemplo, un carácter numérico nos indicará que el token que sigue es de tipo 3 (literal numérico), y debemos pasar el tratamiento a la rutina correspondiente.
La siguiente rutina hace precisamente este trabajo:
procedure NextToken();
//Lee un token y devuelve el texto en "srcToken" y el tipo en "srcToktyp".
//Mueve la posición de lectura al siguiente token.
begin
srcToktyp := 9; //Desconocido por defecto
if next_is_EOF()=1 then begin
srcToken := '';
srcToktyp := 10; //Devuelve token EOF
exit;
end;
if next_is_EOL()=1 then begin
//Estamos al fin de una línea.
srcToken := '';
srcToktyp := 0; //Devolvemos Fin de línea
NextLine(); //Movemos cursor al siguiente token.
end else begin
srcChar := ord(srcLine[idxLine]);
//Hay caracteres por leer en la línea
if IsAlphaUp()=1then begin
ExtractIdentifier();
exit;
end else if IsAlphaDown()=1 then begin
ExtractIdentifier();
exit;
end else if srcChar = ord('_') then begin
ExtractIdentifier();
end else if IsNumeric()=1 then begin
ExtractNumber();
end else if srcChar = ord(' ') then begin
ExtractSpace();
end else if srcChar = 9 then begin //Tab
ExtractSpace();
end else if srcChar = ord('"') then begin
ExtractString();
end else if srcChar = ord('>') then begin
srcToktyp := 6; //Operador
NextChar(); //Pasa al siguiente
if srcChar = ord('=') then begin //Es >=
srcToken := '>=';
NextChar(); //Pasa al siguiente
end else begin //Es ">"
srcToken := '>';
end;
end else if srcChar = ord('<') then begin
srcToktyp := 6; //Operador
NextChar(); //Pasa al siguiente
if srcChar = ord('=') then begin //Es <=
srcToken := '<=';
NextChar(); //Pasa al siguiente
end else if srcChar = ord('>') then begin //Es <>
srcToken := '<>';
NextChar(); //Pasa al siguiente
end else begin //Es ">"
srcToken := '<';
end;
end else if srcChar = ord('/') then begin
if NextCharIs('/') = 1 then begin //Es comentario
ExtractComment();
end else begin
srcToken := '/'; //Acumula
srcToktyp := 9; //Desconocido
NextChar(); //Pasa al siguiente
end;
end else begin //Cualquier otro caso
srcToken := chr(srcChar); //Acumula
srcToktyp := 9; //Desconocido
NextChar(); //Pasa al siguiente
end;
end;
end;
Este procedimiento permite, ahora sí, leer el archivo fuente y determinar a que tipo de token pertenece el carácter actual para luego ir extrayendo los caracteres que corresponden a ese token, devolviendo el token en «srcToken» y el tipo en «srcToktyp».
La identificación de comentarios, tiene un nivel de complicación adicional por cuanto se requiere de dos caracteres «//» para una identificación confiable y no confundir con el operador de división. Para ello se ha implementado la función NextCharIs() que permite «echar un vistazo» al siguiente carácter, porque si se llama dos veces a NextChar() y se encontrara que no se tiene el símbolo «//» ya no habría forma de volver atrás, para continuar con una exploración normal. Lógicamente existen muchas formas de enfrentar este problema, pero lo que aquí planteo es solo una solución práctica basada en mi experiencia como desarrollador.
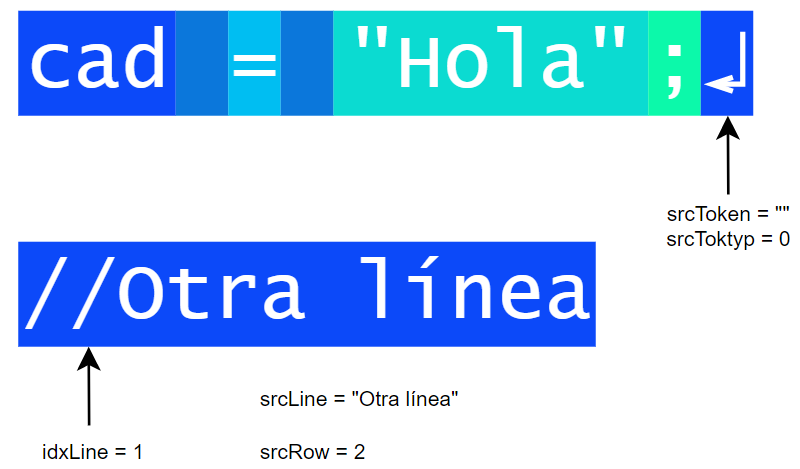
Con cada llamada que se haga a NextToken(), se tendrá un nuevo token en «srcToken» (y su correspondiente tipo en «srcToktyp»), mientras no se llegue al final del archivo.
Las variables «srcLine» almacenará el contenido de la línea actual y «srcRow» indicará el número de línea leído del archivo fuente. Sin embargo, una situación especial se produce al llegar al final de la línea, porque las variables «srcToken» y «srcToktyp» estarán reflejando el estado de la línea anterior, porque para cuando el token actual sea el salto de línea, «srcLine» contendrá ya a la siguiente línea. El siguiente diagrama ilustra esta situación.
El siguiente código integra todas las rutinas vistas anteriormente y ahora sí podemos decir que tenemos ya a nuestro analizador léxico completo incluyendo a la función NextCharIs():
{Proyecto de un compilador con implementación mínima para ser autocontenido.}
program titan;
//Manejo de código fuente
var inFile : Text; //Archivo de entrada
var outFile : Text; //Archivo de salida
var idxLine : integer; //Índice al siguiente token.
var srcLine : string; //Línea leída actualmente
var srcRow : integer; //Número de línea actual
//Campos relativos a la lectura de tokens
var srcChar : integer; //Caracter leído actualmente
var srcToken : string; //Token actual
var srcToktyp : integer; //Tipo de token
function next_is_EOL(): integer;
//Devuelve 1 si el siguiente token corresponde a un Fin de Línea (EOL).
begin
if idxLine > length(srcLine) then begin
exit(1);
end else begin
exit(0);
end;
end;
function next_is_EOF(): integer;
//Devuelve 1 si el siguiente token corresponde a un Fin de Archivo (EOF).
begin
if eof(inFile) then begin
//Ya no hay más líneas pero aún hay que asegurarse de que estamos al
//final de la línea anterior.
if next_is_EOL()=1 then begin exit(1)
end else begin exit(0); end;
end else begin
exit(0);
end;
end;
procedure NextLine();
//Pasa a la siguiente línea del archivo de entrada
begin
if eof(inFile) then begin exit; end;
readln(inFile, srcLine); //Lee nueva línea
inc(srcRow);
idxLine:=1; //Apunta a primer caracter
end;
procedure NextChar();
//Incrementa "idxLine". Pasa al siguiente caracter.
begin
idxLine := idxLine + 1; //Pasa al siguiente caracter
//Actualiza "srcChar"
if next_is_EOL()=1 then begin //No hay más caracteres
srcChar := 0;
end else begin
srcChar := ord(srcLine[idxLine]);
end;
end;
function NextCharIs(car: string): integer;
//Devuelve TRUE(1) si el siguiente caracter (no el actual) es "car".
begin
if idxLine > length(srcLine)-1 then begin exit(0); end;
if srcLine[idxLine+1] = car then begin exit(1); end;
exit(0);
end;
function IsAlphaUp(): integer;
//Indica si el caracter en "srcChar" es alfabético mayúscula.
begin
if srcChar>=ord('A') then begin
if srcChar<=ord('Z') then begin
exit(1);
end else begin
exit(0);
end;
end else begin
exit(0);
end;
end;
function IsAlphaDown(): integer;
//Indica si el caracter en "srcChar" es alfabético minúscula.
begin
if srcChar>=ord('a') then begin
if srcChar<=ord('z') then begin
exit(1);
end else begin
exit(0);
end;
end else begin
exit(0);
end;
end;
function IsNumeric(): integer;
//Indica si el caracter en "srcChar" es numérico.
begin
if srcChar>=ord('0') then begin
if srcChar<=ord('9') then begin
exit(1);
end else begin
exit(0);
end;
end else begin
exit(0);
end;
end;
procedure ExtractIdentifier();
var
IsToken: integer; //Variable temporal
begin
srcToken := '';
srcToktyp := 2;
IsToken := 1;
while IsToken=1 do begin
srcToken := srcToken + chr(srcChar); //Acumula
NextChar(); //Pasa al siguiente
if next_is_EOL()=1 then begin //No hay más caracteres
exit;
end;
IsToken := IsAlphaUp() or IsAlphaDown();
IsToken := IsToken or IsNumeric();
end;
end;
procedure ExtractSpace();
var
IsToken: integer; //Variable temporal
begin
srcToken := '';
srcToktyp := 1;
IsToken := 1;
while IsToken=1 do begin
srcToken := srcToken + chr(srcChar); //Acumula
NextChar(); //Pasa al siguiente
if next_is_EOL()=1 then begin //No hay más caracteres
exit;
end;
if srcChar = ord(' ') then begin
IsToken := 1;
end else if srcChar = 9 then begin
IsToken := 1;
end else begin
IsToken := 0;
end;
end;
end;
procedure ExtractNumber();
var
IsToken: integer; //Variable temporal
begin
srcToken := '';
srcToktyp := 3;
IsToken := 1;
while IsToken=1 do begin
srcToken := srcToken + chr(srcChar); //Acumula
NextChar(); //Pasa al siguiente
if next_is_EOL()=1 then begin //No hay más caracteres
exit;
end;
IsToken := IsNumeric();
end;
end;
procedure ExtractString();
var
IsToken: integer; //Variable temporal
begin
srcToken := '';
srcToktyp := 4;
IsToken := 1;
while IsToken=1 do begin
srcToken := srcToken + chr(srcChar); //Acumula
NextChar(); //Pasa al siguiente
if next_is_EOL()=1 then begin //No hay más caracteres
exit;
end;
if srcChar <> ord('"') then begin
IsToken := 1; //True
end else begin
IsToken := 0; //False
end;
end;
NextChar(); //Toma la comilla final
srcToken := srcToken + '"'; //Acumula
end;
procedure ExtractComment();
begin
srcToken := '';
srcToktyp := 5;
while next_is_EOL()=0 do begin
srcToken := srcToken + chr(srcChar); //Acumula
NextChar(); //Toma caracter
end;
end;
procedure NextToken();
//Lee un token y devuelve el texto en "srcToken" y el tipo en "srcToktyp".
//Mueve la posición de lectura al siguiente token.
begin
srcToktyp := 9; //Desconocido por defecto
if next_is_EOF()=1 then begin
srcToken := '';
srcToktyp := 10; //Devuelve token EOF
exit;
end;
if next_is_EOL()=1 then begin
//Estamos al fin de una línea.
srcToken := '';
srcToktyp := 0; //Devolvemos Fin de línea
NextLine(); //Movemos cursor al siguiente token.
end else begin
srcChar := ord(srcLine[idxLine]);
//Hay caracteres por leer en la línea
if IsAlphaUp()=1then begin
ExtractIdentifier();
exit;
end else if IsAlphaDown()=1 then begin
ExtractIdentifier();
exit;
end else if srcChar = ord('_') then begin
ExtractIdentifier();
end else if IsNumeric()=1 then begin
ExtractNumber();
end else if srcChar = ord(' ') then begin
ExtractSpace();
end else if srcChar = 9 then begin //Tab
ExtractSpace();
end else if srcChar = ord('"') then begin
ExtractString();
end else if srcChar = ord('>') then begin
srcToktyp := 6; //Operador
NextChar(); //Pasa al siguiente
if srcChar = ord('=') then begin //Es >=
srcToken := '>=';
NextChar(); //Pasa al siguiente
end else begin //Es ">"
srcToken := '>';
end;
end else if srcChar = ord('<') then begin
srcToktyp := 6; //Operador
NextChar(); //Pasa al siguiente
if srcChar = ord('=') then begin //Es <=
srcToken := '<=';
NextChar(); //Pasa al siguiente
end else if srcChar = ord('>') then begin //Es <>
srcToken := '<>';
NextChar(); //Pasa al siguiente
end else begin //Es ">"
srcToken := '<';
end;
end else if srcChar = ord('/') then begin
if NextCharIs('/') = 1 then begin //Es comentario
ExtractComment();
end else begin
srcToken := '/'; //Acumula
srcToktyp := 9; //Desconocido
NextChar(); //Pasa al siguiente
end;
end else begin //Cualquier otro caso
srcToken := chr(srcChar); //Acumula
srcToktyp := 9; //Desconocido
NextChar(); //Pasa al siguiente
end;
end;
end;
begin
//Abre archivo de entrada
AssignFile(inFile, 'input.tit');
Reset(inFile);
NextLine; //Para hacer la primera lectura.
while next_is_EOF<>1 do begin
NextToken;
writeln(srcToken);
end;
Close(inFile);
ReadLn;
end.Este código de poco más de 250 líneas será nuestro analizador léxico completo. Aún hay rutinas que iremos completando y tal vez unas leves modificaciones, pero de cualquier forma, serán cambios menores.
Si archivo de entrada contiene el texto mostrado:
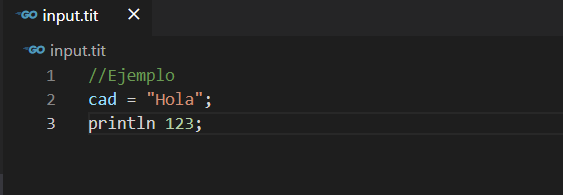
Al ejecutar nuestro programa, veremos que nos muestra en pantalla todos los tokens que tenemos en nuestro archivo fuente:
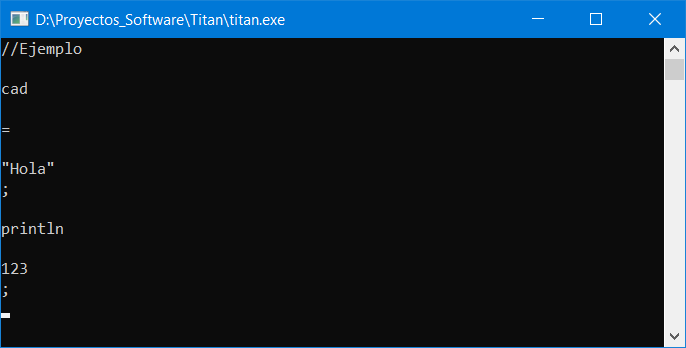
Cada línea de la salida, representa un token y es la salida esperada. Aunque los comentarios se extraen también como tokens no son útiles para el compilador. Estos son solo útiles para el que escribe el programa, así que serán descartados.
Notar que los saltos de línea también se consideran como tokens, aunque sin representación. Lo mismo ocurre con los espacios. Estos si contienen caracteres de espacio pero lógicamente no son visibles en el terminal.
Los otros tokens sí se extraen de manera natural y tienen la apariencia esperada.
En la siguiente parte de esta serie veremos algunas rutinas complementarias del lexer y como podemos usarlas para hacer un análisis sintáctico y hasta empezaremos generando código sencillo.
![]() ¿Cómo citar este artículo?
¿Cómo citar este artículo?
- En APA: Hinostroza, T. (19 de enero de 2019). Crea tu propio compilador – Cap. 6 – Completando el analizador léxico. Blog de Tito. https://blogdetito.com/2019/01/19/crea-tu-propio-compilador-parte-6/
- En IEEE: T. Hinostroza. (2019, enero 19). Crea tu propio compilador – Cap. 6 – Completando el analizador léxico. Blog de Tito. [Online]. Available: https://blogdetito.com/2019/01/19/crea-tu-propio-compilador-parte-6/
- En ICONTEC: HINOSTROZA, Tito. Crea tu propio compilador – Cap. 6 – Completando el analizador léxico [blog]. Blog de Tito. Lima Perú. 19 de enero de 2019. Disponible en: https://blogdetito.com/2019/01/19/crea-tu-propio-compilador-parte-6/
Dejar una contestacion