

8.1 Introducción
En el artículo anterior iniciamos la implementación del analizador sintáctico y definimos la forma en que vamos a manejar los errores en tiempo de compilación.
En este artículo crearemos las plantillas para el análisis de las instrucciones y declaraciones de Titan y empezaremos a crear las rutinas necesarias para la generación de verdadero código ensamblador Intel, que es una de las novedades de este artículo.
8.2 Teoría de Compiladores
Pasadas y fases
Otro de los conceptos que se usan al describir los compiladores, es la «pasada». Una pasada consiste en una exploración completa del código fuente o alguna representación intermedia. Una pasada puede servir para:
- Generar el código objeto o binario directamente.
- Generar alguna representación intermedia del código fuente.
Conviene distinguir lo que es una fase de una pasada del compilador. Ambos conceptos son hasta cierto punto independientes, porque un compilador puede realizar todas las fases en una sola pasada o realizar una pasada para cada fase.
Del número de pasadas que realiza un compilador, se puede aplicar la siguiente clasificación:
- Compilador de una sola pasada.- Realizan todas las fases en una sola pasada. Son compiladores muy rápidos pero sus opciones de optimización se encuentran limitadas.
- Compiladores de varias pasadas.- Es el tipo más común de compilador. Permiten optimizar mejor el código generado.
Compiladores de una sola pasada
En compiladores de una pasada, el compilador realizará una exploración completa del código fuente realizando el análisis sintáctico, y las verificaciones semánticas correspondientes, llamando a las rutinas del analizador léxico, como si de una librería se tratara.
Esta forma de trabajo se puede apreciar en el siguiente diagrama:
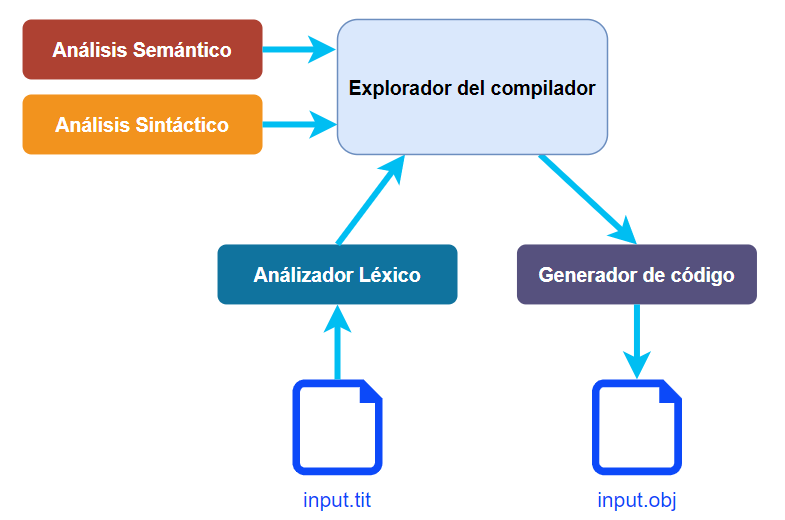
Conforme el compilador vaya realizando la exploración del código fuente, irá generando también el código objeto o de salida, de forma casi paralela. Esta es la forma como trabajará nuestro compilador Titan.
Como el análisis léxico, sintáctico y semántico se realizan en la misma exploración, en este tipo de compiladores suele ser difícil la identificación independiente de cada fase, pero es casi seguro que todas estas fases se estén realizando.
Realizar todas las fases en simultáneo, mientras se explora el archivo fuente, permite una compilación bastante rápida, pero limita las opciones que tiene un compilador de múltiples pasadas, como la posibilidad de realizar optimizaciones sobre el código generado.
Compiladores de múltiples pasadas
Un compilador de múltiples pasadas puede realizar una o varias fases por cada pasada. Lo común es que se haga una fase distinta por cada pasada y que la salida de esa fase sea la entrada para la siguiente pasada. En este tipo de compiladores se suele usar una o varias representaciones intermedias, y también se favorece la optimización del código generado.
Esquematizando el funcionamiento de este tipo de compiladores tendríamos el siguiente diagrama:
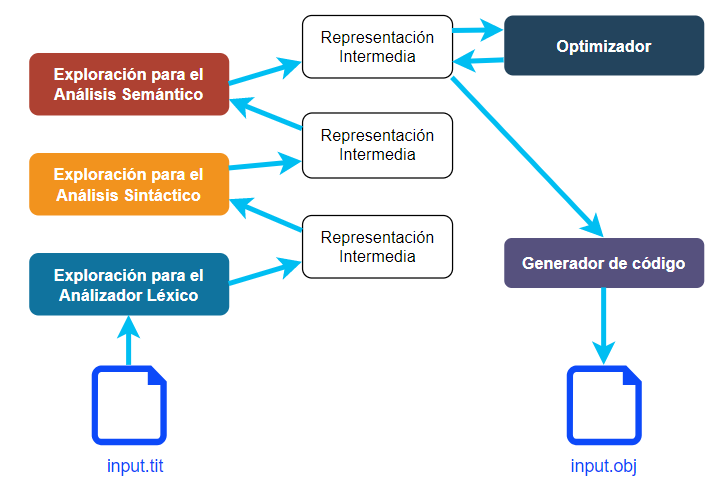
En este esquema de trabajo, que es solo uno de muchos posibles, se puede apreciara que el análisis léxico produce una representación que bien puede ser una lista o árbol de sintaxis conteniendo a todos los tokens reconocidos del archivo de entrada. Este proceso, al que podríamos llamar «tokenizer» es muy similar al mecanismo que usaban las computadoras antiguas, como las Commodore 64 o ZX Spectrum, para reducir el tamaño de los programas en memoria cuando se ingresaban a memoria. De todas formas no es un proceso que se use mucho actualmente, porque el análisis léxico se usa en conjunto con el análisis sintáctico, pero tener una representación intermedia para los tokens leídos puede representar una ventaja, porque dicha representación es más rápida para leer que el código fuente original.
En caso de que el Análisis léxico produzca una representación intermedia, el Análisis Sintáctico trabajará sobre esa representación intermedia. En caso contrario trabajará directamente sobre el código fuente. En cualquier caso, es común que la salida del Analizador Sintáctico sea una representación intermedia del tipo Árbol de Sintaxis Abstracto o similar.
El análisis semántico, si es que se hace de forma separada, puede trabajar también sobre el árbol de sintaxis generado por el Analizador Sintáctico, o también puede crear su propia representación intermedia.
La optimización, aunque puede generar su propia representación intermedia, también puede trabajar modificando la misma estructura de datos que lee.
La generación de código puede generar diversas representaciones intermedias adicionales, o generar directamente el archivo de salida dependiendo de su diseño. Diversos compiladores generan primero un archivo ensamblador antes de generar un ejecutable. Este archivo ensamblador puede considerarse también como una representación intermedia, si no es el producto final del compilador.
De cualquier forma, aunque nos ayuda en el análisis y síntesis, el uso de diversas representaciones intermedias, hay que considerar que requieren más memoria y más consumo de CPU.
Algunos compiladores incluyen una etapa adicional que es llamada el «Preprocesado» del código fuente y que está encargado a un Preprocesador. Este preprocesador tiene como objetivo realizar algunas tareas previas que el compilador no puede (limitaciones técnicas) o no debe (limitaciones de diseño) realizar. Los lenguajes más representativos por el uso de sus preprocesadores son C y C++.
8.3 Análisis del código fuente
Si bien a nivel léxico, no nos interesan las instrucciones del lenguaje Titan, porque la extracción de tokens es totalmente indiferente al orden en que deben ponerse estos tokens e inclusive el mismo lexer podría también usarse para otro lenguaje de programación con poca o ninguna modificación, a nivel sintáctico y semántico sí es determinante conocer la estructura de las instrucciones de nuestro lenguaje de programación.
Para poder analizar sintácticamente el código fuente de un programa en Titan, necesitamos conocer las reglas sintácticas de nuestro lenguaje. Eso ya lo definimos en el Capítulo 4, aunque sin la precisión de una definición BNF o similar.
Lo que se puede deducir del lenguaje Titan es que se compone de dos elementos principales: Declaraciones y bloques, y que son los bloques los contenedores de instrucciones.
Para implementar nuestro análisis sintáctico, necesitamos poder identificar a las declaraciones y a cada tipo de instrucción que pueden residir dentro de los bloques.
Las declaraciones dentro de nuestro lenguaje Titan son fáciles de identificar por cuanto:
- Las declaraciones de variables empiezan con la palabra reservada VAR.
- Las declaraciones de procedimientos empiezan con la palabra reservada PROCEDURE.
Como hemos definido una estructura estricta en el orden de las declaraciones, nuestra rutina para el análisis del programa principal sería bastante compacta y tendría la siguiente forma:
procedure ParserProgram;
{Procesa las declaraciones e instrucciones de un programa.}
begin
if EndOfBlock() = 1 then begin exit; end;
//Procesa sección de declaraciones
while srcToken = 'var' do begin //Declaración de variable
//Procesamiento de declaración de variables.
end;
//Procesa sección de procedimientos.
TrimSpaces;
while srcToken = 'procedure' do begin
//Procesamiento de declaración de procedimientos.
end;
//Procesa cuerpo principal (instrucciones).
//...
ProcessBlock; //Procesamos el bloque de código.
end;Esta rutina es solo un esqueleto. Más adelante iremos completando los códigos que procesarán las declaraciones, de momento nos interesa más solo la estructura de la rutina de exploración principal.
Por la forma como se ha definido el código, no se aceptarán declaraciones de variables una vez que se hayan encontrado declaraciones de procedimientos. De esta forma nos aseguraremos de que respetamos la estructura de un programa en Titan.
Como ya indicamos, las declaraciones se detectan por la palabra reservada inicial que hay al inicio de la declaración. La sintaxis de nuestro lenguaje, al estilo de Pascal, nos ayuda en este sentido porque no genera ninguna ambigüedad. Un caso distinto hubiera sido si hubiéramos elegido una sintaxis como la de C, en donde una declaración de variable o de función pueden empezar de la misma forma y se requiere de un procesamiento más elaborado para salvar la ambigüedad.
Aún no tenemos implementadas las rutinas que procesen las declaraciones. Nuestro procesamiento del programa principal se reducirá a una llamada a ProcessBlock() que como vimos en el capítulo anterior, tampoco tiene implementado el procesamiento de instrucciones, y solamente buscará el delimitador «;».
8.4 Tipos de instrucciones
Conocer los tipos de instrucciones nos servirá para la implementación de nuestro analizador sintáctico, que iremos implementando dentro de la rutina ProcessBlock().
Existen diversos tipos de instrucciones que soporta nuestro lenguaje, aunque no tantos tipos como posee un lenguaje de programación moderno.
El primer tipo de instrucción sería la de asignación. Es la que permite asignar valores a las variables:
a = 0;
valor = valor + 1;Estas instrucciones son las más comunes dentro de un programa y se pueden identificar porque el primer token de la instrucción es el nombre de una variable y terminan con una expresión al lado derecho.
Otro tipo de instrucciones serían las llamadas a procedimientos, sean estos del sistema o definidos por el usuario. Estas instrucciones tienen la siguiente forma:
print("Hola");
proc1();Estas instrucciones se pueden reconocer porque contienen el nombre de un procedimiento o función como token inicial.
Otro de los tipos de instrucciones que incluye nuestro lenguaje Titan son las condicionales. Estas instrucciones tienen la forma:
if x>0 then end;Se pueden reconocer estas instrucciones porque inician con el token «if» y terminan con el token «end» correspondiente. Este tipo de instrucciones son especiales porque contiene uno o dos bloques de instrucciones en su interior, es decir, que pueden anidarse. Consideremos por ejemplo el siguiente código:
if x>0 then
x = 0;
if y>0 then
y = 0;
end;
end;Procesar este tipo de instrucciones implica una complejidad mayor. La forma más sencilla de trabajar con estas instrucciones es mediante analizadores recursivos.
Para terminar, también tenemos a la instrucción «while» que es el único tipo de bucles que implementamos en nuestro lenguaje Titan. Este tipo de instrucción tiene la forma:
while x>0 do
//Bloque de instrucciones.
end;Al igual que las condicionales, el bucle WHILE también contiene un bloque de instrucciones (con cero, una o más instrucciones) en su cuerpo.
8.5 Generando ensamblador
Ahora nos centraremos en darle a nuestro compilador, la posibilidad de generar código ensamblador real. Esto es sencillo porque un programa en ensamblador es solo un archivo de texto con las instrucciones apropiadas.
Necesitamos entonces incluir código en nuestro compilador, para crear un archivo de texto a modo de plantilla a la que podamos ir agregando las instrucciones que vayamos generando.
La platilla o esquema general de un programa en ensamblador que implementaremos será bastante simple (Para más información ver el Capítulo 3):
include \masm32\include\masm32rt.inc
.data
.code
end
La sección «.code» es la que incluirá a código ejecutable a diferencia de la sección «.data» que solo contendrá declaraciones. Este programa bastante sencillo puede ensamblarse sin errores, pero fallará en el enlazado, porque se espera un punto de entrada para el programa principal. Por eso nuestra plantilla final será un poco diferente:
include \masm32\include\masm32rt.inc
.data
.code
start:
end start
Que mantiene la misma idea de simplicidad. Desde luego que los programas serán más complejos que esta simple plantilla, que no hace nada, pero esta será nuestra base desde donde comenzar.
Para generar un archivo de salida, donde escribir código ensamblador, tenemos que agregar unas líneas adicionales al programa principal de nuestro compilador:
begin
//Abre archivo de entrada
AssignFile(inFile, 'input.tit');
Reset(inFile);
//Abre archivo de salida
AssignFile(outFile, 'input.asm');
Rewrite(outFile);
//Escribe encabezado de archivo
WriteLn(outFile, ' include \masm32\include\masm32rt.inc');
MsjError := '';
NextLine(); //Prepara primera lectura.
NextToken(); //Lee primer token
ParserProgram(); //Procesa programa.
if MsjError<>'' then begin
//Genera mensaje en un formato apropiado para la detección.
WriteLn('ERROR: input.tit' + ' ('+IntToStr(srcRow) + ',' + IntToStr(idxLine)+'): ' + MsjError);
end;
//Terminó la compilación.
CloseFile(outFile);
CloseFile(inFile);
if MsjError='' then ExitCode:=0 else ExitCode:=1;
end.El código agregado crea el archivo «input.asm», identificado por la variable «outfile», y escribe una sola línea en él. Esta línea es solo para incluir a la librería «\masm32\include\masm32rt.inc».
Las otras líneas de la plantilla en ensamblador serán generadas por la rutina ParserProgram() que es llamada desde este código.
ParserProgram() debe incluir unas instrucciones adicionales para escribir sobre «input.asm». Su código quedaría de la siguiente forma:
procedure ParserProgram;
{Procesa las declaraciones e instrucciones de un programa.}
begin
if EndOfBlock() = 1 then begin exit; end;
//Procesa sección de declaraciones
WriteLn(outFile, ' .data');
while srcToken = 'var' do begin //Declaración de variable
//Procesamiento de declaración de variables.
end;
//Procesa sección de procedimientos.
WriteLn(outFile, ' .code');
//Procedimientos
TrimSpaces;
while srcToken = 'procedure' do begin
//Procesamiento de declaración de procedimientos.
end;
//Procesa cuerpo principal (instrucciones).
WriteLn(outFile, 'start:');
ProcessBlock; //Procesamos el bloque de código.
WriteLn(outFile, ' exit');
WriteLn(outFile, 'end start');
end;Este código generará la plantilla en ensamblador que buscamos, con las secciones .DATA y .CODE, y aunque se trata de un código vacío, es en realidad el primer código, en ensamblador, que genera nuestro compilador.
Aún no tenemos implementadas las rutinas para el tratamiento de declaraciones o de instrucciones (en «ProcessBlock»), pero ya podríamos escribir un programa cualquiera en «input.tit» y veremos que el compilador nos generará un código ASM, vacío pero funcional, en «input.asm».
Para ello podemos compilar todo el proyecto en Lazarus (<Ctrl>+F9) y luego ejecutar al compilador desde VS Code.
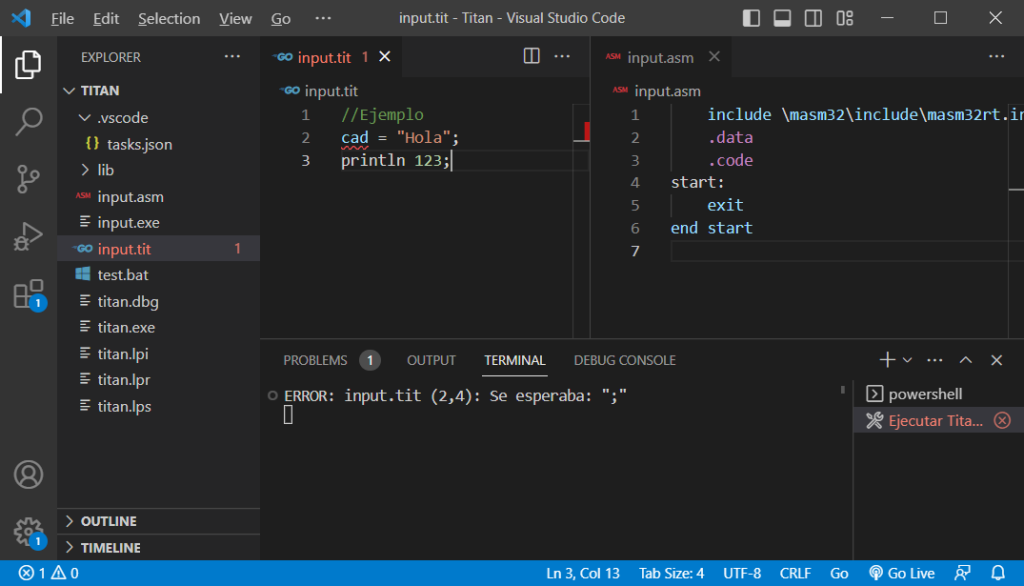
A la derecha podemos ver que aparece ya la plantilla de código en ensamblador que usaremos para agregar las instrucciones.
De momento, se sigue generando un mensaje de error, pero eso es natural porque no tenemos implementado el soporte para ninguna instrucción o declaración.
Como vamos a realizar muchas operaciones de escritura en el archivo ensamblador de salida, y también para evitar usar parámetros repetitivos y expresiones adicionales con cadenas, nos conviene crear un par de procedimientos que escriban directamente en el archivo de salida. Estos procedimientos son:
procedure asmout(lin: string);
//Escribe una línea de ensamblador sin salto de línea.
begin
Write(outFile, lin);
end;
procedure asmline(lin: string);
//Escribe una línea de ensamblador con un salto de línea al final.
begin
WriteLn(outFile, ' ' + lin);
end;Estas dos rutinas son solo una forma cómoda de escribir en el archivo ensamblador de salida, con o sin sangría. La rutina asmline() la usaremos para escribir las instrucciones manteniendo el margen izquierdo como se suele hacer en los programas en ensamblador.
Como siempre, el código fuente completo de este artículo, se encuentra en mi GitHub.
Con los últimos cambios estamos listos para emprender la implementación de las rutinas de análisis sintáctico-semántico. En el siguiente artículo veremos como procesar la declaración de variables en Titan.
![]() ¿Cómo citar este artículo?
¿Cómo citar este artículo?
- En APA: Hinostroza, T. (26 de febrero de 2019). Crea tu propio compilador – Cap. 8 – Empezando a generar código. Blog de Tito. https://blogdetito.com/2019/02/26/crea-tu-propio-compilador-parte-8/
- En IEEE: T. Hinostroza. (2019, febrero 26). Crea tu propio compilador – Cap. 8 – Empezando a generar código. Blog de Tito. [Online]. Available: https://blogdetito.com/2019/02/26/crea-tu-propio-compilador-parte-8/
- En ICONTEC: HINOSTROZA, Tito. Crea tu propio compilador – Cap. 8 – Empezando a generar código [blog]. Blog de Tito. Lima Perú. 26 de febrero de 2019. Disponible en: https://blogdetito.com/2019/02/26/crea-tu-propio-compilador-parte-8/
Dejar una contestacion