

14.1 Introducción
En el capítulo anterior usamos nuestro evaluador de expresiones, que aunque es bastante simple, nos permitió generar código para distintas expresiones numéricas y de cadena, que son los dos únicos tipos de datos que maneja nuestro compilador.
En este capítulo, y por primera vez, le permitiremos a nuestro compilador, poder escribir mensajes en pantalla. Esto nos permitirá, al fin, poder escribir un verdadero «Hola mundo», que es tan importante como cuando escuchamos a un hijo decir sus primeras palabras.
14.2 Teoría de Compiladores
Optimización
La optimización es una de las características más importantes y, aunque no es obligatoria, es hasta cierto punto, imprescindible en compiladores modernos.
El motivo es simple y tiene que ver con una verdad, que no es tan cierta en tiempos modernos, pero que a la letra dice: «Los compiladores son muy malos escribiendo código máquina».
Un compilador sin optimización es solo una máquina de fuerza bruta que traduce de un lenguaje a otro, de manera automática, sin ninguna mejora adicional en el código de salida. El código ejecutable generado por un compilador sin optimización es muy malo en comparación con un código similar escrito en ensamblador por un programador humano.
La utilidad de usar compiladores es precisamente, el evitar escribir código ensamblador, sin perder calidad en el código ejecutable. Y gran parte del éxito de los compiladores actuales se debe a que realizan un buen trabajo de optimización.
Un código optimizado ideal debería cumplir las siguientes características:
- Ser más pequeño que su versión no-optimizada.
- Ser de ejecución más rápida que se versión no-optimizada.
Como no siempre se pueden lograr estas características ideales, algunos compiladores permiten al programador ajustar su optimización para producir código compacto o código rápido, pero no ambos.
Una tarea de optimización clásica puede realizarse en el árbol de sintaxis, mediante un reacomodo o simplificación de los nodos.
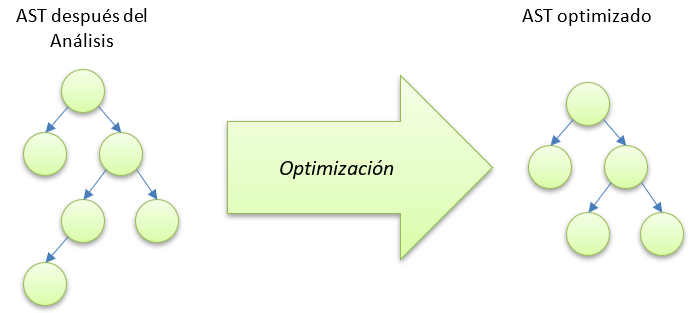
Gran parte de la necesidad de usar representaciones intermedias nace precisamente de la necesidad de poder realizar estas optimizaciones.
Fase de optimización
La optimización es tan importante que existe al menos una fase, dentro del proceso de compilación, dedicada a esta labor.
Un diagrama bastante simplificado de todo el proceso de compilación, podría ser este:
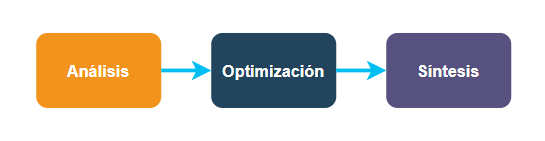
Aunque es posible considerar a la optimización dentro de las fases de análisis o síntesis; se le suele representar como una fase especial separada. Pero eso no implica que todas las tareas de optimización se hagan en una etapa especial y bien diferenciada.
Las optimizaciones de código pueden darse también en las otras fases de la compilación:
- En el análisis. En esta etapa se pueden suprimir algunas instrucciones innecesarias como condicionales vacías o código inalcanzable (por ejemplo después de un RETURN o EXIT).
- En la síntesis. Algunas optimizaciones deben esperar hasta esta fase porque las optimizaciones a aplicar dependen de la arquitectura de hardware para la cual se compila.
Tipos de optimización
Las optimizaciones pueden ser de distinto tipo, y si bien, hay algunas técnicas muy conocidas; no todos los compiladores usan las mismas técnicas de optimización. Algunas de las técnicas más comunes son:
- Variables y funciones no usadas
- Plegado de constantes
- Propagación de constantes
- Eliminación de código muerto
Se pueden aplicar muchas técnicas de optimización en un mismo compilador, pero por lo general, cada técnica de optimización implica una pasada adicional a alguna representación intermedia del compilador, haciendo que el tiempo final de compilación se incremente considerablemente.
Por eso, algunos compiladores, como los de C++, toman un tiempo considerable para la compilación, debiendo recurrir a distintas técnicas para acelerar el tiempo final de compilación.
Una de las técnicas es usar pocas opciones de compilación, durante el proceso de desarrollo (El modo «Debug») y usar mayores opciones de optimización en el modo de producción (El modo «Release»).
Un detalle que debe tenerse siempre en consideración es que un código muy optimizado, refleja poco al código fuente original, trayendo como consecuencia que algunas opciones de depuración (como ejecución paso a paso o la inspección de resultados intermedios) no sean aplicables a un código demasiado optimizado.
14.3 Un alto en el camino
Hasta el momento, el código fuente de nuestro compilador ha ido creciendo y adquiriendo más capacidades. En este punto conviene recordar que nuestro diseño de compilador es bastante simplista en comparación con lo que sería un verdadero compilador, y que solo lo creamos con fines didácticos, pero aún así mantiene un diseño, el mismo que describiremos en las siguientes líneas.
Para empezar tenemos la sección de declaración de variables globales, que son la mayoría de variables, porque se evita usar variables locales para tener un código bastante simplificado.
Luego tenemos la sección de funciones del analizador léxico:
- function next_is_EOL: integer;
- function next_is_EOF: integer;
- procedure NextLine;
- procedure NextChar;
- function NextCharIs(car: string): integer;
- function IsAlphaUp: integer;
- function IsAlphaDown: integer;
- function IsNumeric: integer;
- procedure ExtractIdentifier;
- procedure ExtractSpace;
- procedure ExtractNumber;
- procedure ExtractString;
- procedure ExtractComment;
- procedure NextToken;
Estas funciones son la que reconocen y extraen los tokens del archivo fuente de entrada. El token actual se almacena en la variable «srcToken» y el tipo del token se guarda en «srcToktyp».
Luego incluimos un conjunto de funciones que incluyen el análisis sintáctico y semántico. Algunas de ellas son:
- procedure TrimSpaces;
- function Capture(c: string): integer;
- function EndOfBlock(): integer;
- function EndOfInstruction(): integer;
- function EndOfExpression(): integer;
- procedure ParserVar;
- procedure FindVariable;
- procedure ReadArrayIndex;
Recordemos que, por simplicidad, no estamos incluyendo un módulo de análisis sintáctico independiente, porque haría demasiado complejo a nuestro compilador, que es lo que queremos evitar. En nuestra implementación, de una sola pasada, realizamos el análisis sintáctico y semántico a la vez. E inclusive, la generación de código, o síntesis, la realizamos mientras hacemos el análisis sintáctico-semántico.
La generación de código, se hace principalmente en la función de evaluación de expresiones, que se implementa con diversas funciones:
- GetOperand;
- procedure GetOperand1;
- procedure GetOperand2;
- procedure DeclareConstantString(constStr: string);
- procedure OperAdd;
- procedure OperSub;
- procedure OperOr();
- procedure EvaluateExpression;
14.4 Creando nuestra función «print»
Hasta ahora nuestro compilador solo ha podido procesar declaraciones y expresiones. Pero ahora necesitamos que reconozca nuestra primera función del sistema. Esta primera función será la función «print», la que nos permitirá escribir mensajes en pantalla.
Para implementar esta función, podemos usar diferentes métodos dentro del MASM32, pero en este caso he elegido usar una macro que permite escribir mensajes por pantalla. Esto nos ayudará, porque de otra forma, tendríamos que lidiar con oscuras llamadas a la BIOS o sus equivalentes.
La macro «print» del MASM32 es fácil de usar, como se muestra en el siguiente código ensamblador de ejemplo:
.code
start:
print "Hola"
exit
end startPara imprimir un mensaje en pantalla solo debemos detectar cuando se llama a la función «print» y escribir la instrucción «print» del ensamblador con el parámetro correspondiente.
Como sabemos que nuestro evaluador de expresiones devuelve números en EAX y cadenas en «_strA»; nuestra generación de código debería considerar esos dos casos. Si tan solo tuviéramos que imprimir cadenas; nuestro procedimiento de síntesis sería:
procedure processPrint(ln: integer);
begin
NextToken(); //Pasa del "print"
EvaluateExpression();
if MsjError<>'' then begin exit; end;
//Imprime constante cadena
asmline('print addr _strA');
end;
Que escribe la macro «print» del ensamblador con el parámetro adecuado para mostrar el contenido de una cadena.
Ya luego tan solo deberíamos llamar a esta función para cuando encontremos una llamada a la función «print» en nuestro programa en Titan. Es decir, nuestra instrucción «print» en Titan, se convertirá en la macro «print» del MASM32. La similitud de nombres es solo una coincidencia. Bien pudimos haber llamado con cualquier otro nombre a nuestra instrucción para imprimir en pantalla. Le hemos puesto «print» cuando definimos el lenguaje, pero pudimos haber usado «escribir», «imprimir» o algo similar.
Imprimir una variable, numérica, implica que tenemos que convertir primero el valor numérico a su representación en una cadena. Esto es necesario porque, por ejemplo, el valor numérico 123, almacenado en una variable, es solo un conjunto de bits, que nada tiene que ver con los caracteres ASCII «1», «2», y «3» que deseamos mostrar en la consola.
Para realizar la conversión, nos ayudaremos de otra de las funciones que nos ofrece el MASM32 y se llama «dwtoa». Así que en nuestro compilador, las instrucciones de tipo «print variable_numerica» se deben convertir primero en una llamada a «dwtoa» y luego una llamada a la macro «print», algo como esto:
invoke dwtoa, variable_numerica , addr _strA';
print addr _strA;Notar que el resultado en texto de la conversión de nuestra variable numérica, se almacenará en nuestra zona temporal de memoria «_strA», que nos cae muy bien en este caso.
Finalmente, nuestra función que implementa la generación de código para la instrucción «print», sería esta:
procedure processPrint(ln: integer);
begin
NextToken(); //Pasa del "print"
EvaluateExpression();
if MsjError<>'' then begin exit; end;
if resType = 1 then begin
//Imprime variable entera
asmline('invoke dwtoa, eax, addr _strA');
if ln=0 then begin
asmline('print addr _strA');
end else begin
asmline('print addr _strA,13,10');
end;
end else if resType = 2 then begin
//Imprime constante cadena
if ln=0 then begin
asmline('print addr _strA');
end else begin
asmline('print addr _strA,13,10');
end;
end;
end;
El código es más largo de lo que se necesitaría porque se está aprovechando para implementar otra instrucción de nuestro lenguaje Titan, que es «println» que hace lo mismo que «print» pero que agrega un salto de línea al final. Para ello se debe poner el parámetro «ln» en 1.
Una vez agregada esta función ya tenemos soporte para imprimir en pantalla con «print» y «println», pero aún debemos interceptar las llamadas a estas instrucciones desde dentro de nuestro código fuente. Eso lo hacemos en el procedimiento PorcessBlock() agregando las siguientes instrucciones:
procedure ProcessBlock;
begin
while EndOfBlock()<>1 do begin
if srcToken = 'print' then begin
processPrint(0);
if MsjError<>'' then begin break; end;
end else if srcToken = 'println' then begin
processPrint(1);
if MsjError<>'' then begin break; end;
end else if srcToktyp = 2 then begin
//Es un identificador, debe ser una asignación
ProcessAssigment();
if MsjError<>'' then begin break; end;
end else begin
MsjError := 'Instrucción desconocida: ' + srcToken;
break;
end;
//Verifica delimitador de instrucción
Capture(';');
if MsjError<>'' then begin exit; end;
end;
end;Y ya con esto tenemos soporte para «print» y «println» y, finalmente, podremos mandar mensajes por pantalla.
14.5 Probando la función
Hagamos la prueba con nuestro primer «Hola mundo». Compilemos a nuestro compilador con los nuevos cambios y creemos el siguiente programa en Titan, en el archivo input.tit:
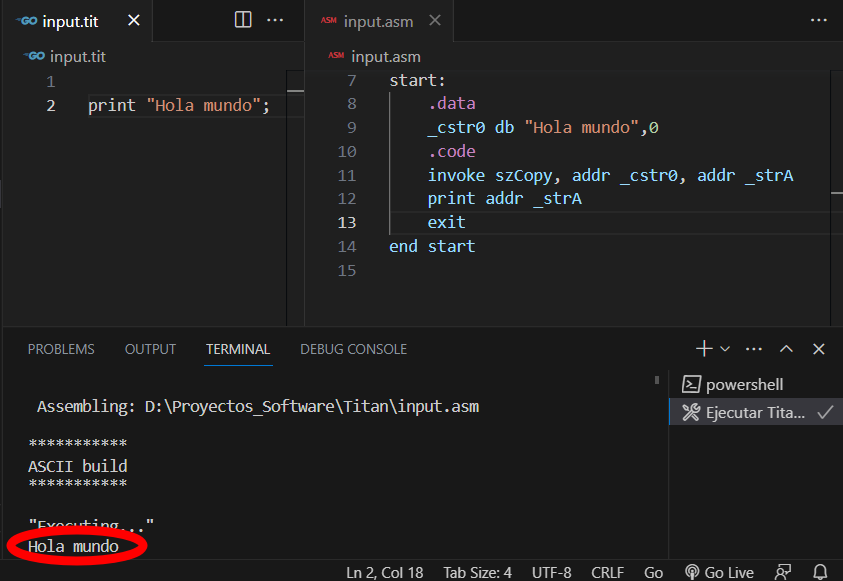
Este es nuestro primer programa que imprime un mensaje en pantalla. El mensaje no imprime el salto de línea final por lo que si imprimimos otra cadena, esta aparecerá a su derecha.
Pero nuestro procedimiento no solo imprime literales de cadena. Es capaz de imprimir expresiones numéricas también:
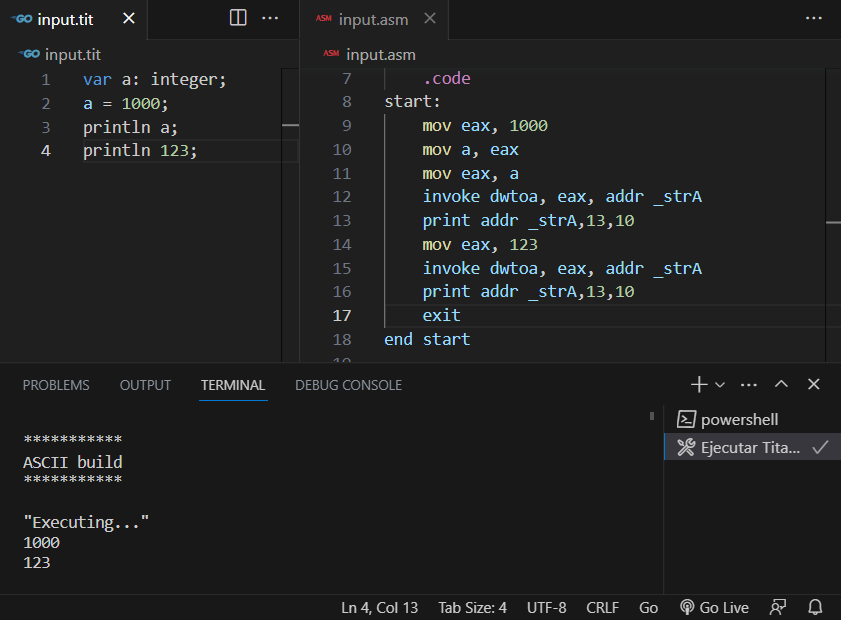
Observar la llamada previa a «dwtoa» y el uso de «_strA» al momento de imprimir variables numéricas.
Aún más, podemos dejar que nuestro evaluador de expresiones trabaje en conjunto para imprimir expresiones sencillas:
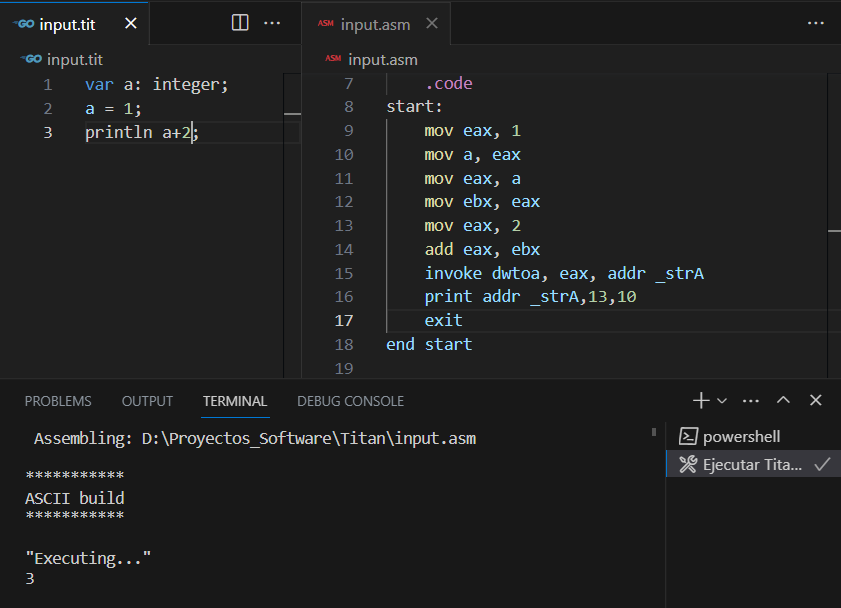
Una revisión del código ASM generado nos ayuda a entender la magia que hace el compilador. El truco está en que primero se llama al evaluador de expresiones y luego a la rutina processPrint().
Hasta ahora hemos logrado un gran avance con nuestro compilador. En el siguiente artículo estaremos revisando y completando algunas funciones que quedan pendientes.
Como siempre, el código fuente del compilador y el proyecto en Lazarus, están publicados en https://github.com/t-edson/CreaTuCompilador.
![]() ¿Cómo citar este artículo?
¿Cómo citar este artículo?
- En APA: Hinostroza, T. (27 de octubre de 2021). Crea tu propio compilador – Cap. 14 – Funciones del sistema. Blog de Tito. https://blogdetito.com/2021/10/27/crea-tu-propio-compilador-parte-14/
- En IEEE: T. Hinostroza. (2021, octubre 27). Crea tu propio compilador – Cap. 14 – Funciones del sistema. Blog de Tito. [Online]. Available: https://blogdetito.com/2021/10/27/crea-tu-propio-compilador-parte-14/
- En ICONTEC: HINOSTROZA, TIto. Crea tu propio compilador – Cap. 14 – Funciones del sistema [blog]. Blog de Tito. Lima Perú. 27 de octubre de 2021. Disponible en: https://blogdetito.com/2021/10/27/crea-tu-propio-compilador-parte-14/
Dejar una contestacion