

Como una ayuda para aquellos que no están familiarizados con el lenguaje ensamblador del Intel x86 de 32 bits o para quienes simplemente quieran refrescar la memoria, va esta sección. Por lo mismo, si el lector tiene buen conocimiento del tema, puede pasar por alto esta sección
Este no es un curso detallado de ensamblador, sino tan solo un repaso de los conceptos que necesitaremos manejar para entender mejor el funcionamiento del compilador.
El ensamblador que usaremos será el MASM32, así que los ejemplos estarán escritos en la sintaxis de este ensamblador, ni más ni menos.
Se necesita conocer el lenguaje ensamblador porque este es el lenguaje destino que estará generando nuestro compilador Titan. Otra opción sería generar código hexadecimal o binario puro, directamente, que pueda ejecutar la CPU, pero, para no complicar en demasía esta aventura, he decidido usar un ensamblador externo.
El MASM32 es un ensamblador que incluye características que podrían considerarse «de alto nivel», y que nos ahorrará mucho trabajo en la generación de código. De otra forma, necesitaríamos incluir mucha lógica adicional en nuestro compilador, que no ayudaría en el objetivo de ser un proyecto sencillo.
3.1 La arquitectura de nuestra CPU
A diferencia de cuando programamos en un lenguaje de alto nivel, cuando programamos en ensamblador necesitamos conocer bien la arquitectura de nuestra CPU, porque, al ser el ensamblador un lenguaje de alto nivel, trabaja muy cerca del hardware.
Ante todo hay que aclarar que las CPU actuales como las Intel Core i7 o Core i5 son máquinas complejas de varios núcleos trabajando a 64 bits y hasta 128 bits en algunos de sus registros.
Para nuestro compilador hemos decidido que solo generaremos código de 32 bits así que solo nos interesa la arquitectura de la CPU a este nivel, y en particular, los registros disponibles.
Centrándonos en los registros que maneja la CPU, la arquitectura simplificada, se parece a la que se muestra en la siguiente figura:
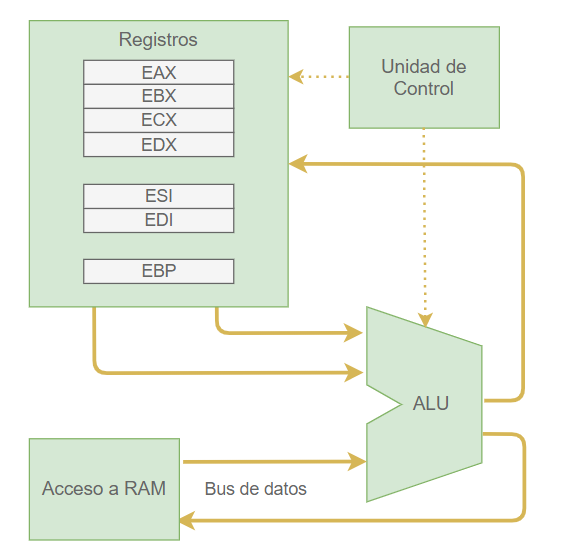
Este diagrama está orientado a mostrarnos el flujo de datos desde y hacia la Unidad Aritmético Lógica (ALU).
Los registros son como pequeñas cajas o zonas de memoria interna de la CPU sobre las que se puede realizar, directamente, las principales operaciones de copia, inicialización, operaciones aritméticas y operaciones lógicas, que es lo que básicamente soporta toda CPU. Los registros tienen una longitud de 32 bits.
La ALU es quien realiza las operaciones básicas que soporta el procesador, como la suma, resta o las operaciones AND y OR. Los datos, sobre los que puede operar la ALU, casi siempre provienen de los registros y terminan en ellos, pero la ALU también puede operar sobre datos de la memoria RAM con ciertas limitaciones.
Los registros principales o de propósito general, son EAX, EBX, ECX y EDX. Sobre ellos se realizan las operaciones principales.
Físicamente, estos registros se implementan dentro del chip como un conjunto de 32 bits, que se pueden leer, o modificar.
Desde el punto de vista práctico, un registro se puede entender como una variable numérica, de tamaño fijo, que puede contener un número que va desde 0 hasta 2^32.
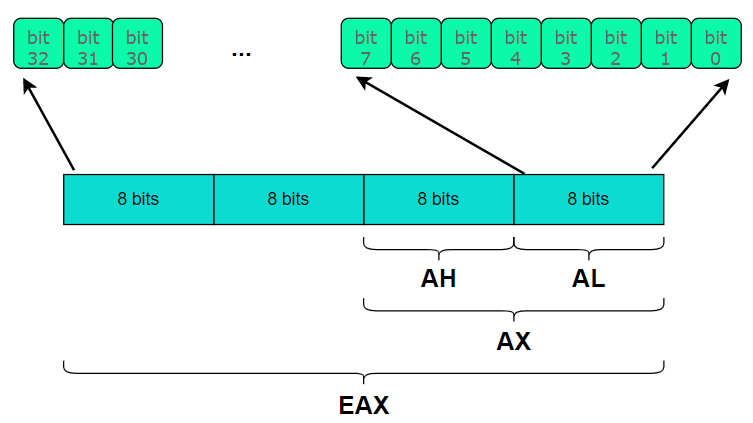
Desde el punto de vista de la CPU, un registro de 32 bits se puede ver también como registros más pequeños de 8 o de 16 bits.
Las instrucciones que puede ejecutar la CPU son diversas y se pueden agrupar en:
- Instrucciones de movimiento. Como MOV o PUSH.
- Aritméticas y lógicas. Como ADD o AND.
- De comparación y control. Como CMP o JNE.
- Instrucciones de cadenas. Como MOVSB o STOSW.
Para una lista detallada de las instrucciones existentes, se puede consultar a este enlace.
3.2 Trabajando con registros
Antes de empezar a escribir código en ensamblador, conviene recordar que la sintaxis del lenguaje ensamblador depende no solo de la marca (en nuestro caso Intel) y la arquitectura destino (en nuestro caso x86 de 32 bits), sino que también dependerá del ensamblador que estemos usando.
En el mundo de Intel existen dos corrientes de ensambladores, ya bastante establecidos:
- Sintaxis AT&T: Usa prefijos para los registros y las direcciones de memoria, además el operando destino va siempre al final: movl $1,%eax
- Sintaxis Intel: No usa prefijos para registros o memoria y el operando destino va siempre al inicio: mov eax,1
Para nuestro trabajo trabajaremos con la sintaxis de Intel, porque estaremos usando el ensamblador MASM32, que trabaja precisamente en esa sintaxis.
Luego de aclarado esta diferencia en los ensambladores, empecemos analizando una instrucción sencilla como esta:
mov EAX, 0x1234Esta instrucción cargará directamente el valor 0X1234 en el registro EAX (Puede llamarse también «eax»):
El sentido del movimiento, para la instrucción MOV va de derecha a izquierda:
MOV <destino> <– <origen>
Esta instrucción «MOV EAX, 0x1234», después de ensamblarse, se convertirá a un conjunto de códigos binarios (algo como 0xB8, 0x34, 0x12, 0x00, 0x00), listo para su ejecución desde la RAM.
También es posible cargar valores desde memoria a los registros:
mov EBX, datoMueve el valor localizado en la zona de la memoria RAM, etiquetada como «dato», al registro EBX .
Si la CPU pudiera operar de manera eficiente, sobre la memoria RAM, los registros no serían tan necesarios [1. Se puede notar, por ejemplo, que las CPU antiguos, cuya velocidad de acceso a la RAM era tan rápida como su velocidad de procesamiento, podían trabajar con muy pocos registros. Este el el caso de la CPU 6502.]. Por ello los programas en ensamblador suelen tener el siguiente flujo de trabajo:
- Mover datos a los registros. Por lo general vienen de la RAM.
- Operar sobre los registros. El resultado queda también en los registros.
- Devolver resultado de los registros. Por lo general se devuelven a la RAM.
Como un ejemplo de este proceso, consideremos el siguiente programa, para sumar dos número en memoria:
mov eax, firstNumber
mov eax, secondNumber
add eax, ebx
mov sumOfTwoNumbers, eaxLa instrucción ADD realiza una suma entre dos operandos (EAX y EBX), y deposita el resultado en el primero (EAX). Esta es la forma común en que trabajan las instrucciones en ensamblador.
Cuando se puede operar directamente sobre la memoria, conviene hacerlo para ahorrar tiempo y memoria:
mov eax, firstNumber
add eax, secondNumber
mov sumOfTwoNumbers, eaxDesde luego que sería mejor hacer algo como «add firstNumber, secondNumber», pero la CPU no puede ejecutar tal operación directamente. Es por eso que se usan los registros, que son los contenedores de datos que están más «a la mano» de la CPU.
3.3 Estructura de un programa
Los programas del ensamblador MASM32 siguen una estructura similar a otros ensambladores de Intel.
El programa se divide en segmentos o secciones. Los segmentos que nos interesan son la de datos y de código. El siguiente esqueleto de programa nos muestra la declaración de estas secciones:
<declaración>
.stack <datos de la pila>
.data
<declaraciones de datos>
.code
<instrucciones>
endEn este pequeño código, se definen tres segmentos mediante las directivas .STACK, .DATA y .CODE. Existen más directivas, pero las mostrados son los más usadas.
La directiva END no genera código, simplemente define el fin del programa ensamblador o del módulo actual.
Los segmentos .DATA y .CODE no tienen que ser únicos, pueden repetirse dentro del mismo programa.
El siguiente código es un ejemplo de un programa en ensamblador típico (que no hace nada útil) en la sintaxis de MASM32:
.DATA
mem32a DWORD 456423
mem32b DWORD 456423
mem32c DWORD 455423
.CODE
; Programa principal
mov eax, 48
add eax, mem32a
mov eax, mem32b
sub eax, mem32c
ENDPara definir el punto de inicio y fin de un programa, es recomendable usar las directivas .STARTUP y .EXIT como se muestra en el siguiente código:
.CODE
;Código del programa
.STARTUP
;Código principal del programa
.EXIT
ENDLa sección de código que no está dentro de .STARTUP … .EXIT puede usarse para subrutinas adicionales.
Otra forma para definir el punto de inicio del código es usar la etiqueta «start». Esta, le indica al enlazador el punto de entrada para que la aplicación pueda ejecutarse correctamente.
3.4 Hola Mundo
El «Hola mundo» en ensamblador, usando MASM32, no es tan aterrador como se suele pensar:
include \masm32\include\masm32rt.inc
.code
start:
print "Hola mundo",13,10
exit
end startEsta simplicidad se debe, en parte, al hecho de que estamos usando macros y funciones de la librería «masm32rt.inc» (MASM32 Runtime Library), y además porque nuestro hola mundo es una simple aplicación de consola
La instrucción «print» es en realidad la llamada a una macro que incluye el código necesario mostrar el texto en pantalla. Esta macro es una forma elegante de ocultar la complejidad del código de escritura en pantalla.
Los valores 13 y 10 son dos bytes que representan a los caracteres de salto de línea y se agregan al final de la cadena «Hola mundo» para que se mueva el cursor a la siguiente línea luego de imprimir el texto. Así se dejará la pantalla lista para imprimir otra línea y evitaremos problemas con el manejo del «Prompt».
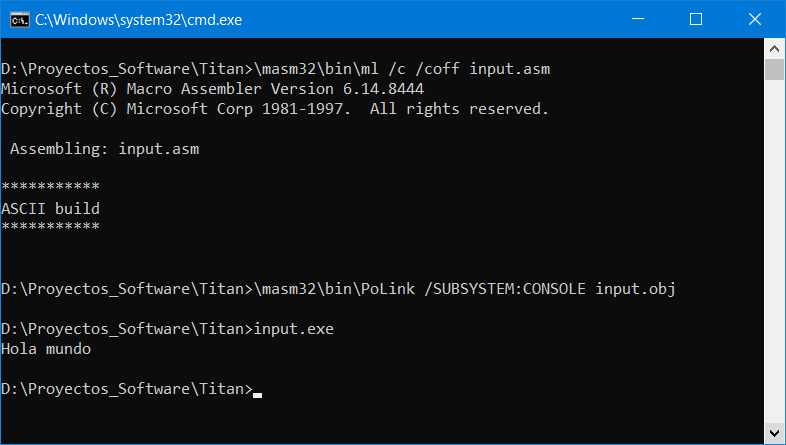
Si ensamblamos, enlazamos y ejecutamos nuestro programa, nos mostrará algo así:
Pero el MASM32 no se agota en aplicaciones para consola. Es totalmente factible crear aplicaciones GUI para Windows. El siguiente ejemplo es un programa que muestra un mensaje en un cuadro de texto, usando las API de Windows:
include \masm32\include\masm32rt.inc
.data
AppName db "GUI Assembler Hello", 0
.code
start:
invoke MessageBox, 0, chr$("Hola Windows"), addr AppName, MB_OK
exit
end startEn este código estamos llamando a la rutina de la API de Windows llamada «MessageBox». Esta llamada la hacemos a través de la macro «invoke» que es la forma común en que se llaman a las subrutinas dentro de Windows.
Nuevamente, vemos que usando la librería «masm32rt.inc» se simplifica, considerablemente, la creación de programas para Windows.
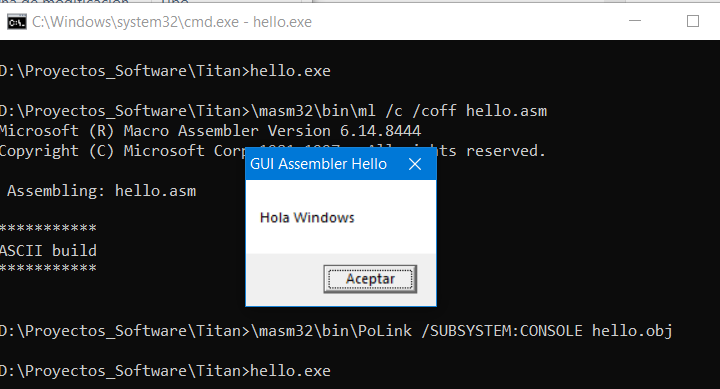
Al ejecutar este programa veríamos una ventana como la que se muestra a continuación:
3.5 Variables en Ensamblador
Las declaraciones de variables en la sintaxis del ensamblador MASM32 se hacen en la sección DATA:
.DATA num1 DB 5 num2 DW 5000 num3 DD 500000 arre1 DB 10 DUP(?)
Este bloque de código define variables de diverso tamaño, como posiciones de memoria en la sección de datos de nuestro programa ensamblador. Existen diversas instrucciones para declarar espacio de memoria:
DB Reserva 1 byte
DW Reserva 2 bytes
DD Reserva 4 bytes
DQ Reserva 8 bytes
DT Reserva 10 bytes
Así, la instrucción:
num1 DW 5000
Indica que se debe reservar 2 bytes de memoria de datos, y se debe inicializar esos datos con el valor 5000.
La instrucción DUP, indica que se debe reservar múltiples elementos de memoria. Por ejemplo, la instrucción:
arre1 DB 10 DUP(?)
Indica que se deben reservar 10 bytes de memoria y no se pide inicializar estos bytes a algún valor en particular. Esta notación no será útil cuando implementemos arreglos.
3.6 Manejo de cadenas
Como se mencionó anteriormente, los registros, que son espacios de almacenamientos de 32 bits, se usan principalmente para almacenar valores numéricos [2. Solo valores enteros, porque para valores en coma flotante existe un procesador matemático especial integrado en la CPU que maneja sus propios registros de mayor tamaño]. Estos valores los expresamos normalmente como:
- 123,
- 0x1A00
- $F000
Todos ellos, se pueden almacenar en registros directamente y trabajarse sobre ellos.
Una cadena de caracteres la representamos comúnmente como:
- «HOLA MUNDO»
- 0x48, 0x4F 0x4C, 0x41, 0x20
Como las cadenas de caracteres suelen ocupar más de 4 bytes (que es lo que nos ofrecen los registros internos de la CPU), se hace necesario almacenarlas en la memoria RAM y procesarlas allí, con ayuda de los registros de la CPU.
La declaración e inicialización de cadenas en RAM se hace en la sección .DATA como en el siguiente código:
.DATA
MY_STRING DB "Contenido de la cadena", 0Casi como un estándar dentro de Windows, y en parte por la proliferación del lenguaje C, se usan las cadenas delimitadas por el carácter Nulo. Es por eso que se suele agregar siempre el carácter 0 al final de la declaración de los literales de cadena.
En este caso, estamos representando las cadenas usando el código ASCII, pero también se pueden trabajar en otras codificaciones como Unicode. De cualquier modo, no dejan de ser bytes almacenados en la RAM a los que se debe acceder por su dirección física.
Afortunadamente, y a pesar de que para la CPU las cadenas no tienen ningún sentido más allá de ser un conjunto ordenado de bytes o «words» en memoria, existen un conjunto muy útil de instrucciones para manipular estas cadenas dentro del ensamblador del Intel x86.
Algunas instrucciones son solo formas resumidas de mover datos y actualizar un registro índice (como LODSB, LODSW o SCASB), pero otras instrucciones son verdaderos bucles optimizados de búsqueda o comparación (Como REPE o REPNE).
Con este conjunto especiales de instrucciones se pueden escribir rutinas bastante eficientes para la manipulación de cadenas, como por ejemplo el siguiente código, permite realizar la búsqueda del carácter espacio en una cadena llamada MY_STRING de 255 caracteres:
.CODE
MOV CX, 255
MOV DI, offset MY_STRING
MOV AL, 20H
REPNE SCASBEn la práctica no se suelen escribir los algoritmos de manipulación de cadenas directamente, sino que se usan las funciones predefinidas de la API que nos ofrece MASM32. Algunas de estas funciones son: szCatStr, szCopy, szLeft, o szLen. El prefijo «sz» nos recuerda que estas funciones trabajan sobre cadenas terminadas con el caracter 0, como comúnmente se hace en el lenguaje C. Una lista más completa de estas funciones se puede ver en el archivo «\masm32\include\masm32.inc» (ubicado en la carpeta donde se encuentra el MASM32 instalado).
Pero además de estas funciones, el archivo de cabecera «\masm32\include\masm32rt.inc» nos da también acceso a las funciones estándar del lenguaje C, definidas en «\masm32\lib\msvcrt.lib».
El siguiente ejemplo muestra cómo leer un texto de consola y a la vez mostrarlo, usando las típicas funciones printf() y scanf():
include \masm32\include\masm32rt.inc
.data
str1 db 'Escribe tu nombre: ',13,10, 0
str2 db '%s',0
str3 db 'Hola %s. Soy un programa.', 0
.data? ;Datos sin inicializar
buffer db 64 dup(?)
.code
start:
invoke crt_printf, ADDR str1
invoke crt_scanf, ADDR str2, ADDR buffer
invoke crt_printf, ADDR str3, ADDR buffer
invoke ExitProcess,0
END startEste programa nos pedirá nuestro nombre, y luego nos mostrará el mismo por pantalla:
3.7 Macros predefinidas
MASM32 no solo nos ayuda en el manejo de las cadenas o estructuras de datos complejas. También nos ofrece un conjunto de macros que implementan las típicas estructuras condicionales como IF o WHILE, que son imprescindibles en los lenguajes de alto nivel.
El siguiente ejemplo, muestra como se puede crear una condición en ensamblador usando la macro .IF:
.IF cx == 20
mov dx, 20
.ELSE
mov dx, 30
.ENDIFDe la misma forma se pueden encontrar macros para bucles WHILE o REPEAT.
También existen un par de macros para el manejo de procedimientos o subrutinas: PROC e INVOKE .
La macro PROC (y su correspondiente delimitador ENDP) permiten definir procedimientos de forma sencilla, sin necesidad de codificar a mano todo el código de inicialización y finalización que se suelen hacer en las subrutinas para administrar correctamente la pila.
El siguiente código de ejemplo, declara un procedimiento que recibe dos parámetros de tipo DWORD.
proc1 PROC par1:DWORD, par2:DWORD
; Cuerpo del procedimiento
ret
proc1 ENDPLa macro INVOKE permite realizar una llamada simplificada a los procedimientos (definidos con PROC o no). Es la forma estándar de llamar a procedimientos dentro de MASM, en el que se usa la pila para pasar los parámetros.
El siguiente ejemplo realiza una llamada al procedimiento definido anteriormente pasándole tres parámetros:
invoke my_proc, NULL, ADDR ClassName, ADDR AppNameA bajo nivel, esta llamada se codificaría como:
push offset AppName
push offset ClassName
push 0h
call my_procEl orden en que los parámetros se ponen en la pila, es el orden inverso en que se declaran, usando PROC.
Resultaría largo explicar el funcionamiento de todas las macros y funciones que nos ofrece MASM32, en un solo artículo. Una descripción más detallada se puede encontrar en la ayuda que viene incluida en el aplicativo MASM32 (Accesible desde el editor principal). Invito al lector a revisar algunos sitios web especializados. Algunos de ellos son:
- http://www.cs.virginia.edu/~evans/cs216/guides/x86.html
- https://www.pcjs.org/documents/books/mspl13/masm/mpguide/
Como hemos visto el MASM32 no es un simple ensamblador que espera que escribamos código ensamblador puro o de bajo nivel, sino que nos ofrece un conjunto de librerías con cantidad de funciones y macros que nos facilitan la labor de escribir un programa al estilo de los lenguajes de alto nivel. Es por ello que a este tipo de herramientas, se les considera como ensambladores de alto nivel.
![]() ¿Cómo citar este artículo?
¿Cómo citar este artículo?
- En APA: Hinostroza, T. (8 de enero de 2019). Crea tu propio compilador – Cap. 3 – Algo de ensamblador. Blog de Tito. https://blogdetito.com/2019/01/08/crea-tu-propio-compilador-parte-3/
- En IEEE: T. Hinostroza. (2019, enero 8). Crea tu propio compilador – Cap. 3 – Algo de ensamblador. Blog de Tito. [Online]. Available: https://blogdetito.com/2019/01/08/crea-tu-propio-compilador-parte-3/
- En ICONTEC: HINOSTROZA, TIto. Crea tu propio compilador – Cap. 3 – Algo de ensamblador [blog]. Blog de Tito. Lima Perú. 8 de enero de 2019. Disponible en: https://blogdetito.com/2019/01/08/crea-tu-propio-compilador-parte-3/
Che ta bueno el curso