

«… Y (Adán) puso nombres a toda bestia y ave de los cielos y a todo animal del campo…»
De ser cierto, el relato, Adán debió tener un trabajo enorme al tener que nombrar a cada criatura viviente, cuando no tenía ni LapTop.
Hace ya varios años, que se creo el estándar Unicode, que permite asignar un código único (punto de código) a cada uno de los miles de caracteres de los idiomas más usados del mundo. Unicode no se restringe solo a caracteres de idiomas específicos. Muchos caracteres y símbolos de diversas disciplinas científicas y artísticas, están también incluidos.
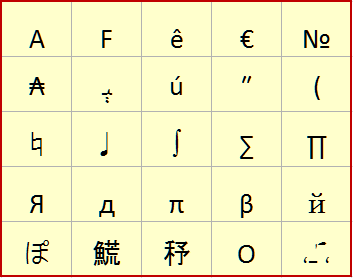
Antes del Unicode, las codificaciones de texto se restringían al código ASCII, que solo cumplía bien con representar los caracteres del alfabeto inglés. Posteriormente se crearon variaciones o extensiones que incluían algunos caracteres latinos y de diversos idiomas además de símbolos gráficos. Aparecieron el ISO-646, CP-437, ISO-8859, Windows-1252, y muchos más.
Si el problema de la incompatibilidad entre codificaciones era ya un problema, aún seguíamos marginando a algunos idiomas como el árabe o el coreano.
Con el advenimiento de internet y la «internacionalización» de la información, se hizo necesario ir más allá de los 8 bits y fue ahí donde nació el Unicode.
Unicode tiene muy buenas intenciones. Es un código supuestamente universal y se aplica a todos los idiomas (con cierta importancia) por igual. Por fin alguien dijo «Vamos a poner orden a esta anarquía de codificaciones de texto». Además UNICODE es compatible con el código ASCII en su primeros 127 códigos.
Pero Unicode no especifica una codificación única. Ahí vienen los problemas. Unicode se puede codificar como UTF-7, UTF-8, UTF-16 o UTF-32. Cada uno tiene un tamaño de código diferente. Por ejemplo UTF-8 va de 1 a 4 bytes, y UTF-16 de 1 o 2 bytes.
Es decir que ahora, además de las codificaciones ya existente, debemos además considerar todas las variaciones de Unicode, que además añade diversidad en el tamaño de los caracteres. Parece que el remedio no es tan efectivo.
Para complicarnos la vida los archivos de texto que se codifican en por ejemplo Windows-1252, contienen códigos validos de UTF-8 y viceversa. Es decir no es posible saber a ciencia cierta, que codificación ha sido usada para un archivo de texto específico. Solo se puede adivinar, intentando cargarlo con una codificación específica y ver si se ve «bien» y si no es así, intentar cargarlo con otra codificación, y así hasta encontrar la que nos guste.
Los textos que solo utilizan los primeros 128 caracteres del código ASCII, no tendrán mayores problemas porque son compatibles en la mayoría de codificaciones. Pero si agregamos códigos como caracteres con tilde o la letra ñ o Ñ, entonces ya tendremos preocupaciones mayores. Desgraciadamente nuestro idioma no se puede manejar sin la letra «ñ».
Hoy en día, los usuarios de computadoras y sobre todo los desarrolladores, no podemos ignorar el caos que existe en las diversas codificaciones para los textos. Además de preocuparnos por decodificar correctamentelos textos, debemos elegir también con qué codificación específica trabajar basándonos también en lo que nuestras herramientas soporten.
Si usted no está convencido de que estas diversas codificaciones de texto le afecten en su vida diaria, le preguntaría ¿No ha tenido usted alguna vez, problemas con las vocales acentuadas o la «ñ» cuando ha escrito o leído un correo electrónico?. Además basta con echar un vistazo al block de notas de Windows para darse cuenta que en la ventana «Guardar Como…» aparece un campo que permite elegir la codificación a usar. El texto también tiene formato.
En mi opinión Unicode se impondrá, y nosotros tendremos que aceptarlo. Recomendaría a los desarrolladores usar el UTF-8 como estándar, porque además, ya está bastante extendido y desarrollado. Las viejas codificaciones deben dejar de ser usadas.
Y a la Real Academia de la Lengua le pediría, tal vez, que nos permita trabajar sin tildes. Así eliminaríamos problemas de compatibilidad y de paso los problemas de ortografía que tanto hacen sufrir a mucha gente. Me incluyo.
También podríamos pedir a los gobiernos que unifiquen sus idiomas, pero ese es un sueño más lejano. ¿Se imaginan cuantas horas hombre, energía y recursos nos ahorraríamos?.
No digo que se olvide la enorme diversidad lingüística del mundo, porque son patrimonio cultural, sino que usemos un idioma estándar (como el esperanto) para comunicarnos todos. La tierra nos lo agradecería.
![]() ¿Cómo citar este artículo?
¿Cómo citar este artículo?
- En APA: Hinostroza, T. (30 de julio de 2013). Unicode o no Unicode – He ahí el dilema. Blog de Tito. https://blogdetito.com/2013/07/30/unicode-o-no-unicode-he-ah-el-dilema/
- En IEEE: T. Hinostroza. (2013, julio 30). Unicode o no Unicode – He ahí el dilema. Blog de Tito. [Online]. Available: https://blogdetito.com/2013/07/30/unicode-o-no-unicode-he-ah-el-dilema/
- En ICONTEC: HINOSTROZA, Tito. Unicode o no Unicode – He ahí el dilema [blog]. Blog de Tito. Lima Perú. 30 de julio de 2013. Disponible en: https://blogdetito.com/2013/07/30/unicode-o-no-unicode-he-ah-el-dilema/
Interesting.
La Tierra nos lo agradecería.