

7.1 Introducción
En el artículo anterior terminamos de construir un analizador léxico (lexer) usando instrucciones sencillas de Pascal, pero cumple bien con su función de extraer tokens. En esta parte implementaremos algunas rutinas necesarias para el analizador sintáctico (parser).
También diseñaremos un sencillo pero efectivo mecanismo para la detección de errores en tiempo de compilación.
Pero como siempre, un poco de teoría de compiladores.
7.2 Teoría de Compiladores
Análisis sintáctico
Como ya comentamos en la introducción teórica del Capítulo 6, el análisis sintáctico está muy relacionado con el análisis léxico pero tienen objetivos diferentes.
El análisis sintáctico valida las reglas sintácticas para asegurarse que el código del programa fuente cumple con la sintaxis definida para el lenguaje que se está manejando.
Así, por ejemplo, si se ha definido que una instrucción de asignación, expresada en la notación BNF, tiene la forma:
<assignment statement> ::= <variable> := <expression>El análisis sintáctico consistirá en verificar, si los tokens de una instrucción, siguen ese patrón y además identificar qué token corresponde a <variable> y cuáles a <expression>.
En este proceso de identificación se pueden encontrar, y reportar, los errores de sintaxis que se puedan ir encontrando.
En la fase de análisis sintáctico se suelen crear algunas estructuras de datos que sirven como apoyo al mismo analizador sintáctico o servirán para las fases posteriores de compilación.
Algunas de estas estructuras son:
- Tabla de símbolos.
- Árbol de sintaxis.
Una tabla de símbolos es una especie de diccionario que da información sobre ciertos tokens que se van identificando en la exploración del código fuente. El objetivo de esta tabla es poder servir como medio de consulta y verificación de ciertos identificadores.
Por ejemplo, si el lenguaje de programación no requiere declaración de variables antes de su uso, podrían ir guardándose las variables que se van detectando en las instrucciones para luego saber qué variables se necesitan crear.
Una tabla de símbolos típica podría tener los siguientes campos:
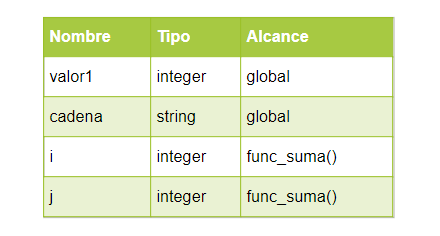
Como una Tabla de símbolos se usará para realizar búsquedas frecuentes, conviene que sea una estructura optimizada para búsquedas.
Otra de las estructuras usadas en el análisis sintáctico es el árbol de sintaxis. Por lo general, el árbol de sintaxis es el producto del trabajo del análisis sintáctico, y que puede servir para el trabajo del análisis semántico, del optimizador o inclusive para el mismo generador de código, si es que no se cuenta con otra representación intermedia más especializada.
A diferencia de una Tabla de símbolos, un árbol de sintaxis tiene una representación jerárquica directa, de modo que modela mejor la sintaxis, en su carácter recursivo.
Un árbol de sintaxis puede ser clasificado en:
- Árbol de sintaxis concreta
- Árbol de sintaxis abstracta.
Un árbol de sintaxis concreta (CST) representa a la sintaxis de forma detalladas, incluyendo símbolos como paréntesis o inclusive espacios o comentarios. La utilidad de un árbol de sintaxis concreto es limitada por lo que no se suele construir este tipo de árbol, debido a quem al tener un número grande de nodos, se complica su análisis, y por otro lado, ocupa más memoria que un Árbol de sintaxis Abstracta.
Las posibles utilidades de un Árbol de sintaxis concreto, que vienen a mi mente son:
- El tener una representación exacta del análisis léxico para la verificación del lexer.
- Servir como fuente de análisis, en lugar del código fuente, cuando se usa algún editor de sintaxis dirigida.
- Servir como paso intermedio para facilitar algún tipo de preprocesamiento adicional.
Un árbol de sintaxis abstracta (AST) es una representación simplificada de un árbol de sintaxis concreta, en donde se suprimen tokens que no aportan valor o que son redundantes. Por ejemplo, los paréntesis en las expresiones no son necesarios en un AST porque cada nodo define ya un nivel de agrupamiento.
Pasemos a mostrar un ejemplo de un AST para un ejemplo de código de asignación:
a := a + 1Un ejemplo de árbol de sintaxis para esta expresión podría ser:
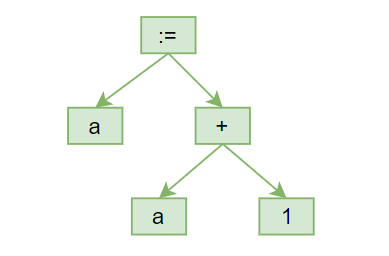
Un AST incluye ya un nivel de agrupamiento que puede considerar la precedencia de operadores, por lo cual resulta muy conveniente para la representación de expresiones.
No hay una estructura estandarizada para la construcción de árboles de sintaxis, ya que dependerá de las necesidades del diseño. Sin embargo, existen herramientas de software que permiten construir arboles de sintaxis concretos y abstractos que se adaptan bien a las necesidades de los compiladores modernos.
En compiladores de una sola pasada, el análisis sintáctico puede ser difícil de identificar de forma separada, como se explicará en el Capítulo 8. En estos casos, el parser es bastante simple y puede que no genere estructuras adicionales como las que se han mencionado aquí.
Manejo de errores
El análisis sintáctico, en nuestro compilador, se basará en revisar las reglas de sintaxis del lenguaje, por lo tanto, existirá una gran probabilidad de encontrar errores, y estos errores deben tratarse adecuadamente.
Un compilador no solo detecta errores en el código fuente, sino que también puede detectar advertencias. Las advertencias son un indicio de que algo puede estar mal, pero no son determinante para predecir un error. Una advertencia puede generarse por algo tan simple como una variable declarada pero no usada, lo cual es más informativo y por lo general no es motivo de preocupación, pero podría ser un indicio de un error en el algoritmo implementado.
Los errores son situaciones críticas que imposibilitan al compilador de poder realizar su trabajo principal de generar un código de salida.
Los errores pueden deberse a errores léxicos (muy pocos casos), sintácticos o semánticos. Otros errores pueden deberse a limitaciones del hardware como «No queda espacio en disco» o «Programa muy grande».
Los errores que se producen en el momento de la compilación, debido al proceso de compilado se llaman «Errores en tiempo de Compilación». Sin embargo, es posible que se produzcan errores en el momento mismo de la ejecución del programa y que no tienen que ver con el compilador. A estos errores se les llama «Errores en tiempo de ejecución» y son los más temidos.
Los lenguajes de programación de tipo «estático» como Pascal o Java, tienden a generar muchos errores a los programadores en el momento de la compilación, pero suelen generar pocos errores en tiempo de ejecución. Los lenguajes dinámicos como PHP o Javascript tienden a generar más errores en tiempo de ejecución.
El comportamiento para procesar los errores, es muy variado, pero podemos considerar estos dos:
- El compilador detiene la compilación y muestra un mensaje de error.
- El compilador pasa el error, muestra el mensaje, y trata de seguir compilando hasta el final.
El primer comportamiento es el más sencillo de implementar, porque solo tenemos que salir de la rutina actual y terminar el programa. Este es el método que usaremos en nuestro compilador Titan, pero podría cambiarse posteriormente.
El último comportamiento es el más común para los compiladores actuales (y algunos de antaño) y se ha usado bastante en compiladores como los de C o Pascal. Esta forma de trabajo, donde se pueden detectar varios errores en una sola pasada del compilador, puede deberse a que en los primeros días de la computación, la compilación era una tarea que podía tomar horas, y nadie deseaba volver a compilar todo, para encontrar el siguiente error. Desgraciadamente un compilador de este tipo (como lo debe saber todo programador de C/C++), suele generar mensajes de error que son dependientes del primer error y que no son errores realmente.
Un compilador, que pueda detectar varios errores en el código fuente, requiere un diseño más complejo y sólido porque necesitará implementar lo que se llama recuperación de un error.
7.3 Rutinas para el análisis sintáctico
Adicionalmente a las rutinas del lexer, incluiremos unas rutinas adicionales cuya función entra en el terreno del análisis sintáctico.
La primera rutina que necesitaremos será la que nos permitirá pasar por alto a los espacios, esto es, ir pasando tokens hasta que encontremos uno que no sea un espacio. Esta rutina es necesaria porque a nivel sintáctico no nos aportan información adicional los espacios.
Los espacios en el código fuente se usan para:
- Separar elementos léxicos. Por ejemplo cuando escribimos «IF a>0 THEN», los espacios de separación son necesarios, sino tendríamos el texto «IFa>0THEN».
- Dar formato al código fuente. Esto es ya un aspecto más de presentación, pero útil, porque permite al código ser más legible.
Para «comernos» esos espacios en blanco hemos creado la siguiente rutina:
procedure TrimSpaces();
//Extrae espacios o comentarios o saltos de línea
begin
while (srcToktyp = 1) or (srcToktyp = 5) or (srcToktyp = 0) do begin
NextToken(); //Pasa al siguiente
end;
end;
Los espacios se identifican por que el tipo de token es 1, pero también se consideran los comentarios (srcToktyp = 5) como si fueran espacios, es decir que también son ignorados, porque son elementos sintácticos que tampoco aportan información.
La rutina TrimSpaces() considera también a los saltos de línea como comentarios o elementos innecesarios porque, cuando definimos nuestro lenguaje, decidimos no hacerlo sensible a los saltos de línea. Por ejemplo, daría lo mismo escribir:
var contador: integer;Que escribir:
var
contador
:
integer
;Si quisiéramos limitar esta libertad en el espaciado, se tendría que modificar esta rutina TrimSpaces() para que no pase por alto los saltos de línea o trabajar con una rutina adicional.
TrimSpaces() es la rutina que más se usará dentro del compilador porque, al ser el lenguaje Titan insensible a los espacios, se llamará siempre antes de buscar algún token en particular.
Otra rutina importante que nos ayudará en el análisis sintáctico y semántico, está referida a la identificación de tokens específicos:
function Capture(c: string): integer ;
//Toma la cadena indicada. Si no la encuentra, genera mensaje de error y devuelve 0.
begin
TrimSpaces;
if srcToken<>c then begin
MsjError := 'Se esperaba: "' + c + '"';
exit(0);
end;
NextToken(); //Toma el caracter
exit(1);
end;
Esta rutina es solo una forma abreviada para extraer un token y verificar si es igual a uno específico, generando un mensaje de error apropiado en caso no se produzca la coincidencia. Esta rutina la usaremos en algunos casos en los que esperamos la aparición de un token específico y cuya ausencia implicaría un error de sintaxis.
La generación de errores se explicará más adelante en la sección 7.5.
Notar el uso de TrimSpaces(). Se usa antes de buscar el token para pasar por alto cualquier espacio en blanco o salto de línea que pudiera haber. Este filtro de espacios previos se usará siempre en cada rutina de análisis sintáctico.
7.4 Jerarquía de elementos
Dentro del análisis sintáctico, nos conviene diferenciar tres distintos niveles de elementos contenedores dentro de nuestro lenguaje Titan. Estos niveles son jerárquicos y se diagraman en la siguiente figura:
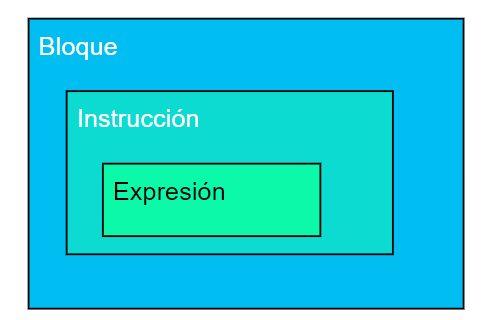
Las expresiones como «a+b» o «a=b» solo pueden aparecer dentro de instrucciones, como en los siguientes casos.
a = a + b; //Instrucción de asignación.
if a=b then a=0; end; //Instrucción condicionalPor eso es que se consideran que las expresiones están incluidas dentro de las instrucciones. Por otro lado, los bloques, como el cuerpo de un programa o de una condicional, se componen de un conjunto de instrucciones, como en el siguiente ejemplo:
if a=b then
//Bloque del cuerpo de la condicional.
a = 0;
b = 0;
end;Para poder identificar expresiones, instrucciones y bloques, nos conviene implementar tres funciones para detectar el fin de estos elementos sintácticos. Estas funciones son:
function EndOfBlock: integer;
//Indica si estamos en el fin de un bloque.
begin
TrimSpaces; //Quita espacios y comentarios.
if srcToktyp = 10 then begin exit(1); end; //Fin de archivo
if srcToken = 'end' then begin exit(1); end;
if srcToken = 'else' then begin exit(1); end;
exit(0);
end;
function EndOfInstruction: integer;
//Indica si estamos en el fin de una instrucción.
begin
if EndOfBlock = 1 then begin exit(1); end;
if srcToken = ';' then begin exit(1); end; //Delimitador
exit(0);
end;
function EndOfExpression: integer;
begin
if EndOfInstruction = 1 then begin exit(1); end;
if srcToken = ',' then begin exit(1); end; //Terminó la expresión
if srcToken = ')' then begin exit(1); end; //Terminó la expresión
if srcToken = ']' then begin exit(1); end; //Terminó la expresión
exit(0);
end;Notar que como existe una relación de inclusión entre los bloques, instrucciones y expresiones, el fin de un bloque implica el fin de una expresión y una instrucción, mientras que el fin de una instrucción implica el fin de una expresión también.
Cada rutina que verifica el límite de un elemento sintáctico, verifica, además, la existencia de algunos tokens que se consideran delimitadores. Por ejemplo, el fin de una instrucción se determina por la existencia del carácter «;».
Las expresiones incluyen diversos tokens delimitadores como «,», «)» o «]» porque las expresiones pueden aparecer en diversas posiciones, en el programa. También se pudo haber incluido el token «THEN» que es el delimitador de las expresiones booleanas de una condicional, pero puesto que hemos definido que las expresiones booleanas tienen una estructura de solo operandos (ver Capítulo 4), no hace falta la verificación del token «THEN». Lo mismo se puede decir de las expresiones para los bucles WHILE … DO.
Estas rutinas de verificación de delimitadores nos ayudarán en el análisis sintáctico de las instrucciones. Así, por ejemplo, podemos empezar con una rutina de procesamiento de bloques de código, de la siguiente forma:
procedure ProcessBlock();
//Procesa un bloque de código.
begin
while EndOfBlock()<>1 do begin
//Procesa la instrucción
// ...
//Verifica delimitador de instrucción
Capture(';');
if MsjError<>'' then begin exit; end;
end;
end;El método de exploración es como se debería de esperar de una rutina que analiza instrucciones, un sencillo bucle WHILE que verifica si se ha llegado al final de un bloque, mientras analiza una a una las posibles instrucciones que puede contener el bloque.
Esta rutina la usaremos para procesar las instrucciones una a una, tanto las que aparecen en el bloque principal como en los cuerpos de los procedimientos, e inclusive la usaremos también para procesar los bloques de las sentencias condicionales y el bucle WHILE.
Más adelante iremos completando el interior de ProcessBlock(). Este es el lugar donde reconoceremos y procesaremos todas las instrucciones de nuestro lenguaje Titan. De momento la dejaremos como una simple plantilla.
ProcessBlock() realiza la exploración principal que realiza el compilador sobre las instrucciones. En nuestro compilador Titan, se realizarán las rutinas de análisis sintáctico, análisis semántico y generación de código, todas dentro de este bucle, como corresponde a un compilador de una sola pasada y como se describirá más adelante en la Sección 9.2.
7.5 Nuestro soporte para errores
Nuestro compilador Titan tendrá un mecanismo sencillo de detección de errores:
- No se generarán advertencias, solamente mensajes de error.
- Todo del proceso de compilación se detendrá al encontrar el primer error.
Para nuestros propósitos necesitamos una variable para almacenar el posible mensaje de error que nuestro compilador pueda generar.
MsjError : string;
Esta variable nos servirá a la vez como bandera, ya que, si no contiene texto, asumiremos que no se han generado errores.
Como ejemplo del mecanismo de detección de errores consideremos el siguiente código de la rutina Capture():
function Capture(c: string): integer ;
//Toma la cadena indicada. Si no la encuentra, genera mensaje de error y devuelve 0.
begin
TrimSpaces();
if srcToken<>c then begin
MsjError := 'Se esperaba: "' + c + '"';
exit(0);
end;
NextToken(); //Toma el carácter
exit(1);
end;Cuando se detecta el error, se pone el mensaje en «MsjError» y se sale de la rutina. Las rutinas de mayor nivel verificarán luego el estado de «MsjError» después de la llamada a cada función que pueda generar error. Este mismo mecanismo, lo usaremos en todas las funciones que puedan generar error.
El siguiente diagrama de secuencia esquematiza este proceso:
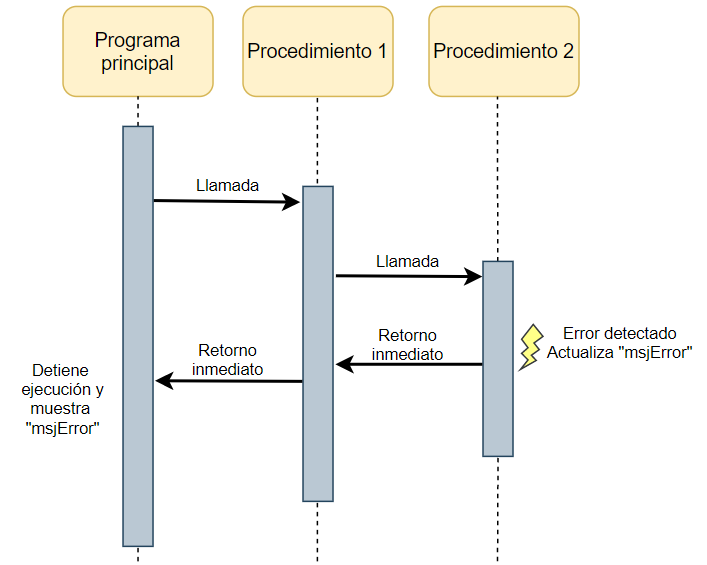
Quizá alguien pueda preguntar ¿Y cómo se sabe el número de línea en que se generó el error?
La respuesta es simple. Recordemos que hemos creado una variable que guarda siempre el número de línea que vamos explorando. Esta variable es «srcRow» y es actualizada en el procedimiento NextLine().
Cada vez que se genera un error, se detiene todo el proceso de compilación y «srcRow» mantendrá él número de la última línea que se ha estado analizando. Puede que este número de línea no sea preciso, porque el compilador puede detectar el error al explorar varias líneas más adelante, pero es una buena aproximación.
La posición del error no solo se identifica por número de fila, sino también por el número de columna, debido a que esta posición se mantiene actualizada en la variable «idxLine», que es el índice al siguiente token a explorar por el lexer. Esta posición tampoco es exacta para ubicar el error con precisión en todos los casos, pero es una ayuda muy útil considerando la simplicidad de nuestro mecanismo de detección de errores.
7.6 Procesamiento del error
La detección de errores (el primero) de nuestro compilador se realiza en el cuerpo principal de nuestro compilador. Pare ello crearemos el programa principal de la siguiente forma:
begin
//Abre archivo de entrada
AssignFile(inFile, 'input.tit');
Reset(inFile);
MsjError := '';
NextLine(); //Prepara primera lectura.
NextToken(); //Lee primer token
ProcessBlock(); //Procesa programa.
if MsjError<>'' then begin
//Genera mensaje en un formato apropiado para la detección.
WriteLn('ERROR: input.tit' + ' ('+IntToStr(srcRow) + ',' + IntToStr(idxLine)+'): ' + MsjError);
end;
Close(inFile);
ReadLn;
if MsjError='' then ExitCode:=0 else ExitCode:=1;
end.Este sencillo programa muestra el proceso que vamos a seguir para la detección de errores y la visualización de mensajes de error.
La primera parte del código, la que corresponde a las instrucciones NextLine() y NextToken() nos sirver para asegurar el correcto funcionamiento del lexer. NextLine() hace la primera lectura del archivo de entrada en la variable «srcLine» e inicializa «idxLine». NextToken() hace la lectura del primer token en las variables «srcToken» y «srcToktyp».
El procesamiento de las instrucciones del programa se hacen con nuestra rutina ProcessBlock() que acabamos de crear y que aún no reconoce ninguna instrucción pero que buscará el delimitador «;» y generará un error si no lo encuentra.
Después de llamar a ProcessBlock() se verifica el estado de la variable y bandera «MsjError», para determinar si se ha producido o no un error. De darse ese caso, se muestra un mensaje por la consola con la forma:
ERROR: input.tit (1,2): Algo salió mal por aquí.
Este formato de mensaje se ha elegido siguiendo la forma común en que muchos aplicativos muestran su mensaje de error. Es útil porque contiene la información necesaria para identificar y ubicar a un error:
- Nombre de archivo que contiene el error.
- Número de fila y columna donde se produce el error.
- Texto del mensaje de error.
Por ahora solo estaremos usando un nombre de archivo pero mantenemos este formato para el futuro.
Teniendo ya avanzado nuestro compilador, con las funciones que hemos incluido en este Capítulo, podemos compilar nuestro programa de ejemplo «input.tit» que contiene el código:
//Ejemplo
cad = "Hola";
println 123;Si ejecutamos nuestro compilador con este archivo de entrada obtendremos el siguiente mensaje de error por la consola:
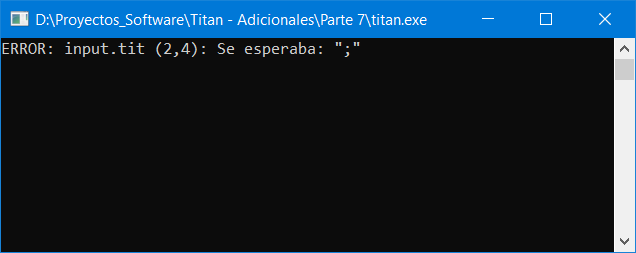
Esto es lo esperado porque nuestra rutina ProcessBlock() aún no está en condiciones de reconocer instrucciones y solo esperará que se encuentre un punto y coma.
La última instrucción del programa:
if MsjError=» then ExitCode:=0 else ExitCode:=1;
Es importante para informar al Sistema Operativa sobre el estado del programa al terminar la ejecución. No es realmente importante actualizar el código de salida para nuestro compilador, pero de esta forma se puede integrar mejor con otras herramientas externas como veremos en la siguiente sección.
7.7 Integración con VS Code
Para facilitar la prueba y desarrollo de nuestro compilador integraremos la salida de nuestro compilador en el editor VS Code.
Para ello, y como ya habíamos indicado en la Sección 2.6, hemos creado una tarea que nos permite ejecutar a nuestro compilador y capturar su salida. Esta tarea tiene la forma que se indica en la figura:
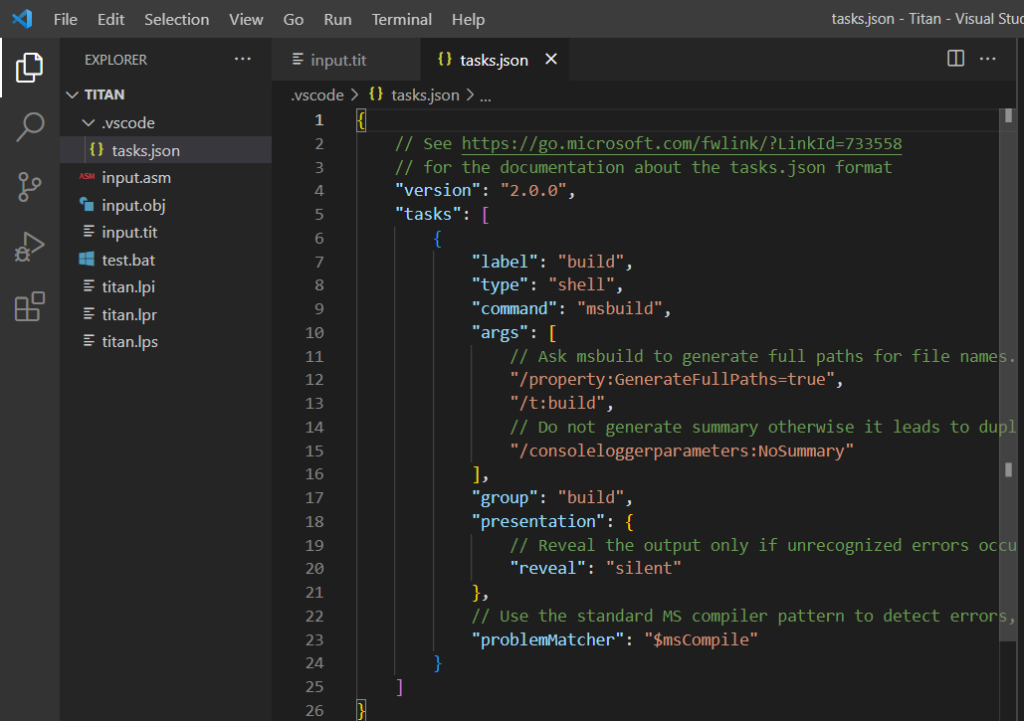
Con esta tarea definida, podemos llamar directamente a nuestro script «test.bat» usando la combinación de teclas <Shift>+<Ctrl>+<B>, y ver su salida en la consola integrada de VS Code:
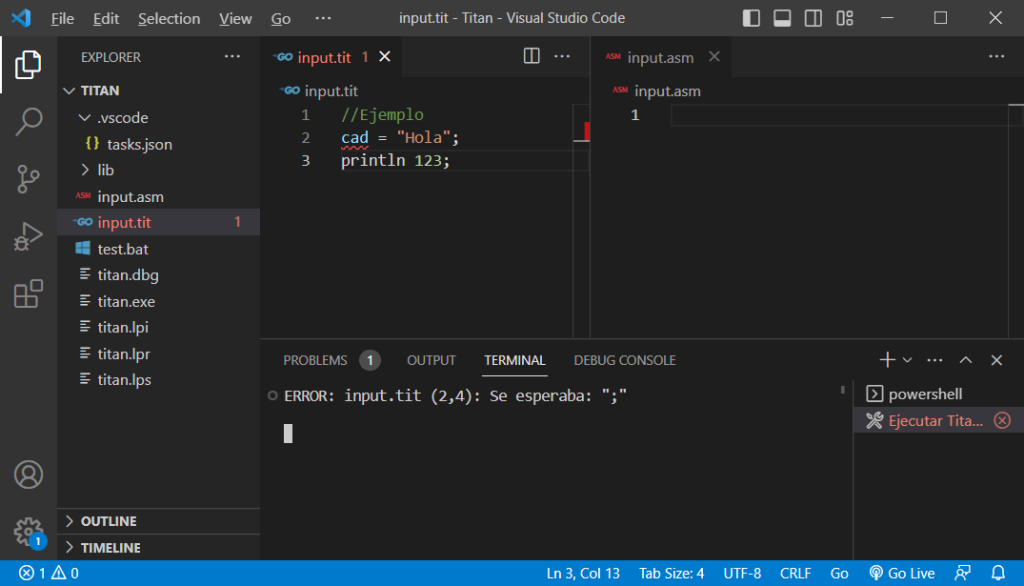
Observar que el mensaje de error de nuestro compilador aparece en el terminal de la parte inferior. Lo que es mejor, nuestra tarea en «tasks,json» también ha sido configurada para detectar los mensajes de error que generamos (en el formato indicado en las sección 7.6) y resaltar el texto en la posición indicada por el mensaje de error, con un subrayado ondulado de color rojo.
Con esta configuración nos será bastante cómodo, modificar nuestro compilador y luego realizar el compilado, ensamblado y enlazado (mediante «test.bat») con una simple combinación de teclas.
Aprovechando este mensaje de error y resaltado que apreciamos en nuestro código de prueba, podemos notar el caso de imprecisión en la ubicación del error.
El fragmento de código de prueba debería dar error en la primera línea porque no incluye el punto y coma que espera ProcessBlock(). Sin embargo, el compilador seguirá buscando el punto y coma, aún en la segunda línea, porque los comentarios se ignorarán y el parser es insensible a los saltos de línea.
Solo al encontrar el token «cad» de la segunda línea se generará el mensaje de error ‘Se esperaba «;»‘. Para ese entonces «srcRow» estará apuntando a la línea 2 e «idxLine» a la columna 4 [1. Para información sobre el funcionamiento del lexer, Ver el Capítulo 6]. Es por eso que el mensaje de error muestra la posición (2,4).
Obtener una ubicación más exacta de un error implicaría el uso de variables adicionales de posición y rutinas más elaboradas para el manejo de errores que nuestro compilador no implementará.
El código fuente completo de este capítulo, tiene casi 350 líneas y, por espacio, no lo incluiré aquí sino que puede ser consultado aquí, en donde están los códigos completos todos los capítulos publicados.
De momento nuestro compilador no puede generar código aún, pero ya incluye algunas rutinas que nos serán útiles para el análisis sintáctico y, además, tiene ya implementado el procesamiento de errores. Antes de continuar con el análisis sintáctico, implementaremos, primero, algunas rutinas básicas del generador de código. Ese tema es, precisamente, el que veremos en el siguiente Capítulo.
![]() ¿Cómo citar este artículo?
¿Cómo citar este artículo?
- En APA: Hinostroza, T. (9 de febrero de 2019). Crea tu propio compilador – Cap. 7 – Análisis sintáctico. Blog de Tito. https://blogdetito.com/2019/02/09/crea-tu-propio-compilador-parte-7/
- En IEEE: T. Hinostroza. (2019, febrero 9). Crea tu propio compilador – Cap. 7 – Análisis sintáctico. Blog de Tito. [Online]. Available: https://blogdetito.com/2019/02/09/crea-tu-propio-compilador-parte-7/
- En ICONTEC: HINOSTROZA, Tito. Crea tu propio compilador – Cap. 7 – Análisis sintáctico [blog]. Blog de Tito. Lima Perú. 9 de febrero de 2019. Disponible en: https://blogdetito.com/2019/02/09/crea-tu-propio-compilador-parte-7/
Muy interesante.
Estaré esperando el siguiente articulo
Muchas gracias, también estaré esperando el próximo artículo.
Me encantaron tus articulos por favor no tardes ya que mi proyecto final es un compilador :´(
Excelente aporte.
los siguientes artículos se encuentran en la pestaña de búsqueda:
Ejemplo : Crea tu propio compilador – Parte 7,8,9…
He estad leyendo los artiulos, y se ve baantente interesante; lo ehcare a andar pronto. Suludos desde Chiapas México