

9.1 Introducción
En el artículo anterior implementamos las primeras rutinas para la generación de código en ensamblador (aún vacío), y creamos las rutinas que nos permitirán procesar a todas las instrucciones que soportará nuestro compilador.
Una de las primeras tareas que debemos implementar en nuestro compilador, como parte del análisis sintáctico, es el reconocimiento de las variables declaradas en el lenguaje Titan. Eso es lo que veremos en este Capítulo.
9.2 Teoría de Compiladores
Las variables
Probablemente los elementos sintácticos más importantes de un programa son las variables. Para el compilador es muy importante identificar a las variables para poder asignarles memoria al momento de la ejecución del programa compilado.
Durante el proceso de compilación, el compilador identifica las variables que va a necesitar para que el programa producto pueda ejecutarse correctamente. Estas variables no solo incluyen a las variables declaradas explícitamente en el código fuente del programa a compilar, sino que también puede incluir a variables adicionales que el programa necesitará, para cálculos intermedios o almacenamiento temporal.
A nivel físico las variables son solo direcciones de memoria en donde se guarda el valor de las variables.

Por comodidad, y porque no se sabe anticipadamente la dirección física en memoria que ocupará una variable resulta más fácil trabajar con nombres (identificadores) en lugar de direcciones físicas (números).
Por ejemplo, cuando declaramos una variable de la siguiente forma:
VAR valor: integer;
Estamos indicando que todas las veces que usemos el identificador «valor» nos estamos refiriendo a la dirección física que asigne el compilador (o más precisamente, el sistema operativo) a la variable «valor».
Para facilitar esta identificación, los compiladores suelen guardar toda la información de las variables en alguna Tabla de Símbolos para facilitar el análisis sintáctico o posterior identificación en el análisis semántico.
La información que se suele guardar sobre las variables en la tabla de símbolos es variable y depende de la implementación del compilador y del lenguaje que soporte. Un caso típico de tabla de símbolos que identifica a variables se puede contener los siguientes parámetros:
- Nombre
- Tipo
- Dirección física
- Almacenamiento
- Alcance
El tipo de una variable indica como debe interpretarse el contenido de la variable y determina también el tamaño que ocupa en memoria y las operaciones que sobre la variable pueden realizarse.
El alcance indica en que contexto o bloque es accesible la variable. Por ejemplo, podría indicar si una variable es accesible globalmente para todo el programa o solo dentro de algún procedimiento o función. Este atributo está relacionado con el almacenamiento de la variable.
Tipos de Memoria RAM
Cuando se dice que las variables se almacenan en RAM, no se especifica en qué parte o en qué tipo de memoria se almacena.
Existen diversos tipos de almacenamiento en RAM, que los sistemas operativos, los dueños de las computadoras, ofrecen a los programas para su ejecución. A pesar, de que las técnicas de manejo de memoria se han vuelto más sofisticadas con el tiempo, al igual que las CPU, todavía se siguen manteniendo los tres tipos de memoria clásica:
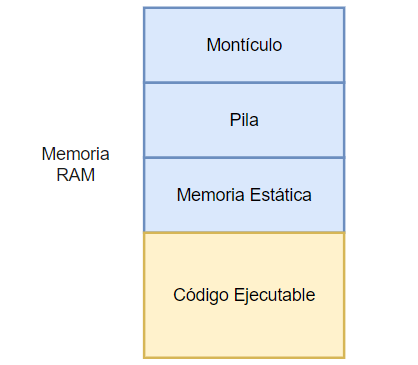
MEMORIA ESTÁTICA
Es la memoria más común usada por los programas. Esta es la memoria más eficiente en cuanto a velocidad de acceso. Se define al momento de iniciar la ejecución de un programa y se mantiene disponible todo el tiempo. Además, su dirección física no cambia, por lo que se accede a ellas mediante su dirección física.
Es la memoria favorita para las variables globales porque existen durante todo el ciclo de vida de ejecución del programa.
Las variables, u objetos que utilizan esta memoria, son llamados variables estáticas u objetos estáticos. Pueden estar inicializados o no.
MEMORIA DE PILA
Es la memoria que utilizará la CPU para sus operaciones de pila. A este tipo de memoria se le llama también «Stack», «Memoria de Stack» o simplemente «La pila».
Todas las CPU modernas, de cierta complejidad, incluyen instrucciones de tipo PUSH o POP, que graban el contenido de sus registros o de RAM en una zona de memoria que se administra como una pila LIFO.
La pila es usada también para las instrucciones de llamada a subrutina (CALL o JSR) y sus correspondientes instrucciones de retorno (RETURN o RTS) por su facilidad para acceder a la última dirección guardada.
EL MONTÍCULO
A esta memoria se le conoce también como «Memoria dinámica», «El montón», o el «Heap» que es su denominación en lengua inglesa.
Este es el tipo de memoria más extraño, pero muy usado actualmente. No se maneja como pila ni como memoria estática. Es memoria RAM común eso es cierto, pero lo que la hace diferente es la forma en que se gestiona.
Esta memoria se va tomando de a trozos o bloques, de acuerdo a la necesidad de los programas, y se van liberando también, cuando el programa decida que ya no lo va a usar.
Debido a este comportamiento , se pueden crear zonas vacías que no pueden usarse porque no tienen el tamaño suficiente y suelen generar fragmentación en la RAM.
Almacenamientos especiales
El principal soporte para el almacenamiento de las variables es la memoria RAM, y solo en casos muy especiales se podrá usar algún tipo de soporte diferente (como el disco duro, memoria EEPROM o Flash).
Sin embargo, y a pesar de que todas las variables se puedan almacenar en RAM, existen situaciones en las que el compilador puede decidir no almacenar los valores de las variables en la RAM. Estos casos especiales, debidos a criterios de optimización, pueden ser:
- Almacenamiento como constante. Este tipo de almacenamiento es el que se usa para las constantes declaradas, pero el compilador puede dar este mismo trato a ciertas variables, que son inicializadas una sola vez y de allí se usan solo para lectura.
- Almacenamiento en registros. En ciertos lenguajes como C, es posible definir explícitamente que una variable se almacene durante todo su ciclo de vida en un registro de la CPU, usando la directiva «register». Pero es posible también que el mismo compilador decida, por optimización, usar registros de la CPU para almacenar a una variable durante todo su ciclo de vida.
- Almacenamiento en banderas. Este es un caso extremo de almacenamiento de registros. Se trata de un caso en que el tamaño de la variable tiene uno o pocos bits y pueden almacenarse directamente en una de las banderas de estado de la CPU. Este tipo de almacenamiento es ideal para almacenar variables booleanas o de tipo bit.
Lo ideal sería que todas las variables pudieran caber completas en los registros de una CPU. Si este fuera el caso, la implementación de compiladores se simplificaría considerablemente, además de mejorar el rendimiento del código ejecutable. Desgraciadamente en muchos casos esto no se cumple. Tal es el caso de los tipos «string», que no solo pueden tener un tamaño de varios bytes, sino que, además, pueden tener un tamaño variable.
9.3 Nuestra estrategia de implementación
Nuestra implementación será simple. Partiremos de la identificación de las declaraciones de variable, mediante el token «var» para pasar a generar directamente las instrucciones ensamblador que corresponden.
Viéndolo así, implementar la declaración de variables en nuestro compilador, consistirá en traducir la declaración de variables en lenguaje Titan, a la declaración de variables en lenguaje ensamblador.
Esta forma de generación de código es un tanto diferente a como trabajan la mayoría de compiladores, pero funcionará bastante bien para nuestro compilador.
En un compilador común, el reconocimiento de variables es también un proceso complejo, ya que las variables pueden ser de tipos diversos y ser a la vez, composición de otras variables, como los arreglos y registros. Además, se debe considerar que las variables pueden tener diferentes alcances (locales, globales o restringidas) y también diversos almacenamientos (estático, dinámico, en pila, …).
En nuestra implementación, sin embargo, solo trabajaremos con dos tipos simples y sus correspondientes arreglos. A pesar de ello, el código necesario es considerable.
9.4 Soporte a variables
Para almacenar información sobre las variables necesitaremos de alguna estructura que nos sirva a modo de «tabla de variables», que no es más que una Tabla de Símbolos. Es decir, una tabla que almacene información importante sobre las variables declaradas que se vayan encontrando. Esto es importante porque las variables, una vez declaradas, pueden aparecer más adelante en el código fuente y se necesitará tener información sobre esas variables (como su existencia y tipo) para validar las reglas semánticas.
Como estamos restringidos a usar datos simples, y eso implica que no podemos usar registros (struct) u objetos, vamos a crear diversos arreglos, cada uno destinado a almacenar un campo en particular:
//Información sobre variables var nVars : integer; //Número de variables. var varNames : array[0..255] of string; var varType : array[0..255] of integer; var varArrSiz : array[0..255] of integer;
Estos tres arreglos, en la práctica, se comportarán como si fuera uno solo de un registro de 3 campos, nuestra tabla de símbolos.
La variable «nVars» nos servirá para almacenar la cantidad de variables que tenemos declaradas de forma global [1. Para las variable locales usaremos otras estructuras de datos como detallaremos más adelante]. El límite para la cantidad de variables, en nuestro humilde compilador, está fijado a un valor estático de 256. Esta limitación la ponemos, porque de momento no podemos manejar estructuras dinámicas en la implementación de Titan y 256 es un número razonable para un compilador pequeño como el nuestro.
Los arreglos varNames[] y varType[] almacenarán el nombre y el tipo de la variable, respectivamente.
Para el tipo de datos, usaremos el siguiente estándar:
1 -> integer
2 -> string
No necesitamos más valores por cuanto hemos definido que en nuestro lenguaje Titan solo manejaremos estos dos tipos.
El arreglo varArrSiz[] nos indicará el tamaño de elementos que tiene la variable. Este valor será útil cuando la variable sea de tipo «arreglo», que también será implementado en nuestro compilador. Si la variable es de un tipo simple, se pondrá a cero su posición correspondiente en varArrSiz[].
Como ejemplo del uso de los arreglos sobre variables, consideremos el caso en que tenemos la siguiente declaración en el lenguaje Titan:
var nombre: string;
var edad: integer;
var arreglo[5]: string;Al procesar esta declaración, deberemos tener los arreglos llenos de la siguiente forma:
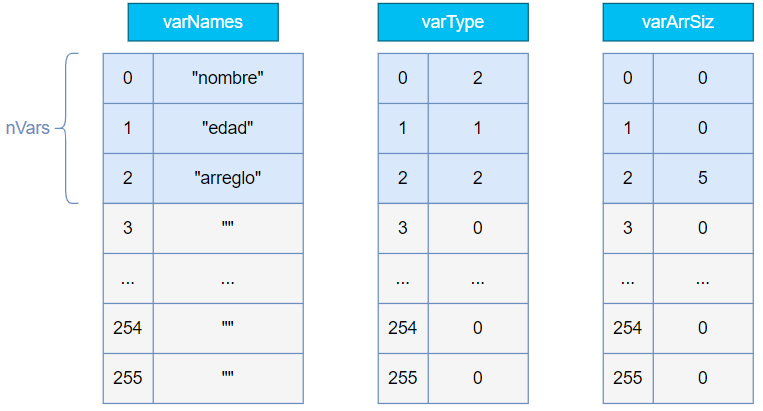
Las posiciones no usadas no tienen valores significativos y no se leerán. Tampoco se inicializan, así que, podrían tener cualquier valor.
9.5 Reconociendo las declaraciones
Con los arreglos creados, ya podemos implementar el reconocimiento de las declaraciones de variables.
Comenzaremos creando una rutina que agregue los datos de una variable a nuestra tabla de símbolos que se compone de los arreglos varNames[], varType[] y varArrSiz[]:
procedure RegisterVar(vName: String; vType: integer; arrSiz: integer);
//Registra una variable en los arreglos correspondientes.
begin
varNames[nVars] := vName;
varType[nVars] := vType;
varArrSiz[nVars]:= arrSiz;
nVars := nVars + 1;
end;
Luego crearemos una rutina que procese la declaración de variables en nuestro compilador. Una versión sencilla de esta rutina podría ser:
procedure ParserVar();
//Hace el análisis sintáctico para la declaración de variables.
var
varName, typName: String;
begin
NextToken(); //Toma el "var"
TrimSpaces(); //Quita espacios
if srcToktyp<>2 then begin
MsjError := 'Se esperaba un identificador.';
exit;
end;
varName := srcToken;
NextToken(); //Toma nombre de variable
TrimSpaces();
//Lee tipo
if srcToken = ':' then begin //Es declaración de tipo común
NextToken(); //Toma ":"
TrimSpaces();
typName := srcToken;
if typName = 'integer' then begin
NextToken(); //Toma token
asmline(varName + ' DD 0');
RegisterVar(varName, 1, 0) //Registra Integer
end else if typName = 'string' then begin
NextToken(); //Toma token
asmline(varName + ' DB 256 dup(0)');
RegisterVar(varName, 2, 0) //Registra String
end else begin
MsjError := 'Tipo desconocido: ' + typName;
exit;
end;
end else begin
MsjError := 'Se esperaba ":" o "[".';
exit;
end;
end;
Esta rutina debe ser llamada cuando se haya detectado que el token actual es «var». El trabajo, que viene luego, consiste en ir extrayendo los tokens de acuerdo con la sintaxis que hemos definido para nuestro lenguaje Titan:
var <nombre de variable>: <tipo>;
Se puede observar que el reconocimiento de tokens es secuencial, y, de no encontrarse el token que se esperaba (como los dos puntos), se genera un mensaje de error actualizando la variable «msjError» y saliendo del procedimiento.
Cuando se ha identificado sin errores la declaración de la variable, se escriben sus datos en los arreglos varNames[], varType[] y varArrSiz[].
El procedimiento ParserVar() es reducido porque solo analiza la declaración de variables simples y porque solo existen dos tipos de datos en nuestro lenguaje. Cuando se detecta la declaración de una variable entera, se genera, en el archivo de salida, la siguiente directiva en ensamblador:
<varName> DD 0
Esta directiva reserva 4 bytes en memoria porque este es el tamaño que usaremos para las variables enteras. Notar que no estamos escribiendo directamente en el archivo ensamblador, sino que estamos usando el procedimiento asmline() que creamos en el Capítulo anterior.
Para las variables de tipo cadena reservaremos 256 bytes en memoria y las inicializaremos a cero, porque usaremos el tipo de cadenas terminadas en el carácter nulo:
<varName> DB 256 dup(0)
La rutina ParserVar() es una versión simplificada que no considera el caso de arreglos, pero es un buen punto de partida para entender al análisis del código fuente.
Para activar en nuestro compilador, el reconocimiento de declaraciones, necesitamos modificar nuestra rutina ParserProgram(), para que pase el procesamiento de variables, a nuestra rutina recién creada:
procedure ParserProgram();
{Procesa las declaraciones e instrucciones de un programa.}
begin
if EndOfBlock() = 1 then begin exit; end;
//Procesa sección de declaraciones
WriteLn(outFile, ' .data');
while srcToken = 'var' do begin //Declaración de variable
ParserVar();
if MsjError<>'' then begin exit; end;
//Verifica delimitador de instrucción
Capture(';');
if MsjError<>'' then begin exit; end;
TrimSpaces();
end;
//Procesa sección de procedimientos.
WriteLn(outFile, ' .code');
//Procedimientos
TrimSpaces;
while srcToken = 'procedure' do begin
//Procesamiento de declaración de procedimientos.
end;
//Procesa cuerpo principal (instrucciones).
WriteLn(outFile, 'start:');
ProcessBlock; //Procesamos el bloque de código.
WriteLn(outFile, ' exit');
WriteLn(outFile, 'end start');
end;
La parte resaltada es el código que se ha agregado para procesar las declaraciones de variables.
Con el nuevo código agregado, ya podríamos «compilar» a nuestro compilador y experimentar con una declaración sencilla de variable como:
var a: integer;
Al compilar este código, desde VS Code (Con <Shift>+<Ctrl>+<B>) obtendremos en nuestro archivo de salida ASM, la declaración de variables en la sintaxis de MASM32.
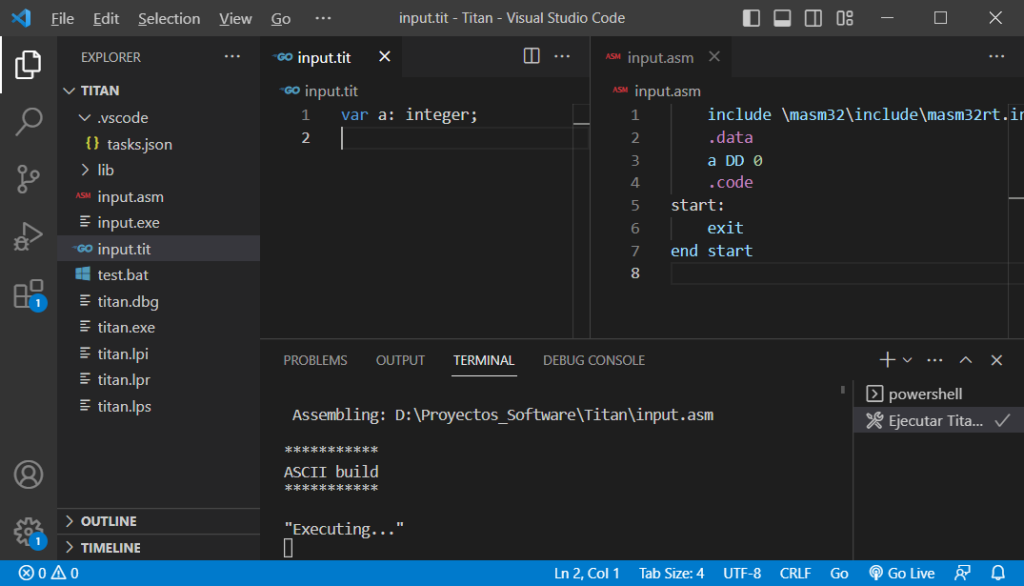
Notar que la ejecución de «test.bat», desde la consola inferior del VS Code, debe producirse sin error. Si se obtiene algún mensaje de error, revisar la implementación de ParserVar().
La instrucción ensamblador, que corresponde a la declaración de la variable «a», es «a DD 0». El código ensamblador generado es sintácticamente válido, pero no ejecutará nada y solo reservará espacio en la memoria para nuestra variable. En los artículos siguientes, cuando generemos verdaderas instrucciones en ensamblador, usaremos estas declaraciones
9.6 Soporte a arreglos
Hasta el momento, la declaración de variables funciona bastante bien, pero solo se remite a variables de tipo simple. Para soportar la declaración de arreglos necesitamos ampliar este código con el procesamiento de los caracteres «[» y «]». La definición de espacio en RAM es sencilla, porque solo basta con multiplicar el tamaño del tipo de dato por el tamaño del arreglo.
El código siguiente es la versión más completa de ParserVar() que soporta la declaración de arreglos de los dos tipos básicos de datos que manejamos en Titan:
procedure ParserVar();
//Hace el análisis sintáctico para la declaración de variables.
var
varName, typName: String;
arrSize: string; //Como cadena para concatenar
arrSizeN: integer; //Como número
arrSize256: string; //Tamaño por 256.
begin
NextToken(); //Toma el "var"
TrimSpaces(); //Quita espacios
if srcToktyp<>2 then begin
MsjError := 'Se esperaba un identificador.';
exit;
end;
varName := srcToken;
NextToken(); //Toma nombre de variable
TrimSpaces();
//Lee tipo
if srcToken = '[' then begin
//Es un arreglo de algún tipo
NextToken(); //Toma el token
TrimSpaces();
if srcToktyp<>3 then begin
MsjError:='Se esperaba número.';
exit;
end;
arrSize := srcToken; //Tamaño del arreglo
arrSizeN := StrToInt(srcToken); //Tamaño del arreglo
arrSize256 := IntToStr(arrSizeN*256);
NextToken();
Capture(']');
if MsjError<>'' then begin exit; end;
//Se espera ":"
Capture(':');
if MsjError<>'' then begin exit; end;
//Debe seguir tipo común
TrimSpaces();
typName := srcToken;
if typName = 'integer' then begin
NextToken(); //Toma token
asmline(varName + ' DD ' + arrSize + ' dup(0)');
RegisterVar(varName, 1, arrSizeN) //Registra arreglo Integer
end else if typName = 'string' then begin
//Debe terminar la línea
NextToken(); //Toma token
asmline(varName + ' DB '+ arrSize256 + ' dup(0)');
RegisterVar(varName, 2, arrSizeN) //Registra arreglo String
end else begin
MsjError := 'Tipo desconocido: ' + typName;
exit;
end;
end else if srcToken = ':' then begin //Es declaración de tipo común
NextToken(); //Toma ":"
TrimSpaces();
typName := srcToken;
if typName = 'integer' then begin
NextToken(); //Toma token
asmline(varName + ' DD 0');
RegisterVar(varName, 1, 0) //Registra Integer
end else if typName = 'string' then begin
NextToken(); //Toma token
asmline(varName + ' DB 256 dup(0)');
RegisterVar(varName, 2, 0) //Registra String
end else begin
MsjError := 'Tipo desconocido: ' + typName;
exit;
end;
end else begin
MsjError := 'Se esperaba ":" o "[".';
exit;
end;
end;
El código adicional que se ha agregado a ParserVar(), y que aparece resaltado en naranja, puede parecer intimidante pero no es muy complejo. Simplemente considera una ampliación para considerar las declaraciones de variables en modo arreglo como: «var x[10]: integer».
El código de soporte para arreglos es muy similar al código normal sin arreglos, excepto por:
- El procesamiento adicional que se hace para obtener el tamaño fijo entre corchetes del arreglo.
- El tamaño final reservado en memoria que es igual al tamaño del arreglo por el tamaño del tipo de dato.
- La necesidad de actualizar el tamaño del arreglo en varArrSiz[].
Si definimos un arreglo de enteros con el siguiente código Titan:
var numeros[5]: integer;El compilador generará la siguiente definición en ensamblador:
numeros DD 5 dup(0)Esta definición crea un arreglo de enteros de 5 números de 4 bytes, es decir, 20 en total. La instrucción «dup(0)» indica que se inicializarán los 5 elementos con el valor 0. Aunque en la práctica, no es necesario inicializar los elementos de un arreglo, es recomendable, si es que no se inicializan arreglos enormes.
Para las cadenas la sintaxis es la misma solo que se crea como arreglo de bytes. La cantidad total de bytes es la cantidad de ítems multiplicada por 256, ya que cada cadena tiene una longitud fija de 256 bytes.
Consideremos, por ejemplo el siguiente arreglo:
var arrnotas[3]: string;Como el tamaño es de 3, el tamaño total en bytes será de 768 bytes, y el compilador generará la siguiente declaración en ensamblador:
arrnotas DB 768 dup(0)Estos 76 bytes se ubican físicamente como un solo bloque, pero lógicamente se manejará como tres cadenas de 256 bytes cada uno, como se indica en el siguiente diagrama:

En este caso hemos asignado las cadenas «Do» y «Re» a los dos primeros elementos de arrnotas[].
Todos los arreglos, dentro de Titan, estarán indexados desde 0 hasta n-1, donde «n» representa el tamaño del arreglo.
Notar que cuando se procesa la declaración de una variable de tipo arreglo, nuestra tabla de símbolos almacenará la siguiente información:
- varNames[] – > El nombre del arreglo
- varType[] -> el tipo del ítem.
- varArrSiz[] -> El tamaño del arreglo
Un detalle menor, en ParserVar(), es que estamos usando variables de tipo cadena para «arrSize» y «arrSize256». Se trabajan de esta manera para facilitar la concatenación de estos valores, al momento de escribir en el archivo ensamblador.
Una vez que hayamos compilado a Titan, podemos ahora hacer unas pruebas con el siguiente código:
var arrnotas[3]: string;
var numeros[5]: integer;Si compilamos esta declaración con Titan, obtendremos el código ensamblador que se muestra en la siguiente figura:
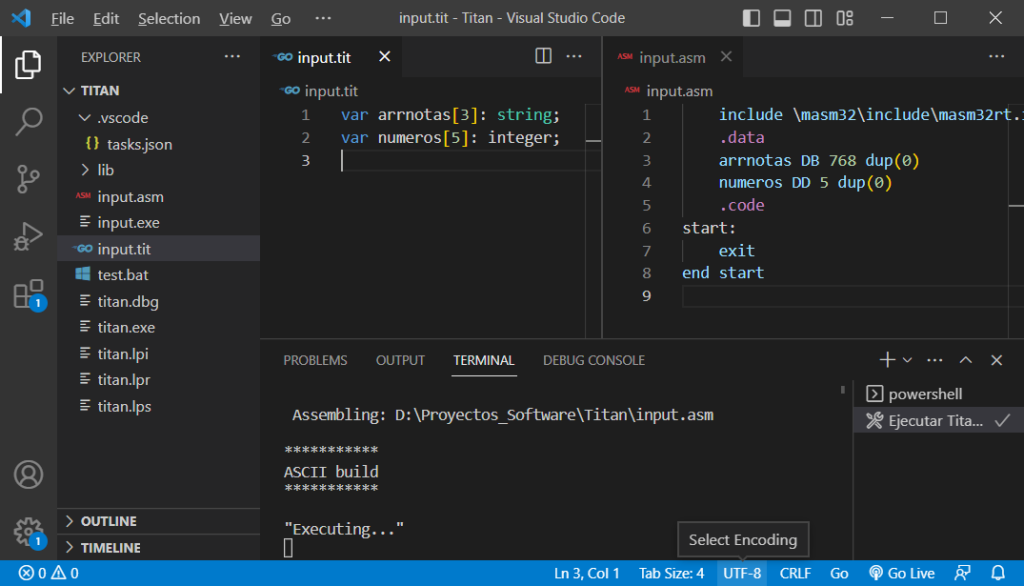
Se pueden incluir declaraciones adicionales de variables y estas serán reconocidas correctamente.
Es altamente recomendable, e instructivo, experimentar con el código de ParserVar() para ver los errores que se generan o tratar de implementar sintaxis diferentes a la que se ha definido para nuestro lenguaje.
En este artículo, hemos conseguido que se reconozcan las declaraciones de variables de nuestro lenguaje, pero aún no se han generado verdaderas instrucciones ejecutables.
En la siguiente parte empezaremos a reconocer expresiones y a generar código ejecutable verdadero, en ensamblador.
![]() ¿Cómo citar este artículo?
¿Cómo citar este artículo?
- En APA: Hinostroza, T. (19 de abril de 2019). Crea tu propio compilador – Cap. 9 – Declaración de variables. Blog de Tito. https://blogdetito.com/2019/04/19/crea-tu-propio-compilador-parte-9/
- En IEEE: T. Hinostroza. (2019, abril 19). Crea tu propio compilador – Cap. 9 – Declaración de variables. Blog de Tito. [Online]. Available: https://blogdetito.com/2019/04/19/crea-tu-propio-compilador-parte-9/
- En ICONTEC: HINOSTROZA, Tito. Crea tu propio compilador – Cap. 9 – Declaración de variables [blog]. Blog de Tito. Lima Perú. 19 de abril de 2019. Disponible en: https://blogdetito.com/2019/04/19/crea-tu-propio-compilador-parte-9/
Dejar una contestacion